Storage Layer와 완전히 분리된 Compute Layer는 하나의 데이터에 대하여 여러가지 워크로드가 액세스 할 수 있다. 스토리지에서 분리되어 있는 특징 때문에 운영 중단 없이 즉각적이고 독립적으로 확장이 가능하다. 또한 워크로드 간의 완벽한 분리가 가능하기 때문에 리소스 경쟁을 제거할 수 있고 트랜잭션의 일관성도 유지할 수 있다.

아래에서 자세히 살펴보자.
1. What is Virtual Warehouse?
Virtual Warehouse는 최신 데이터 웨어하우스를 지원하는 컴퓨팅 클러스터의 또 다른 용어이다. 메모리, 임시 저장소 및 CPU를 포함한 리소스를 제공하여 SQL 실행 및 DML(Data Manipulation Language)을 위해 언제든지 활용하고 필요하지 않을 때 끌 수 있는 독립적인 컴퓨팅 리소스이다.
아래 다이어그램은 Snowflake 아키텍처와 Virtual Warehouse가 Snowflake에 컴퓨팅 서비스를 제공하고 클라우드 서비스 계층에 의해 조정되는 방법을 보여준다.

Virtual Warehouse는 다른 Virtual Warehouse와 컴퓨팅 리소스를 공유하지 않는 독립적인 컴퓨팅 클러스터이다. 좀 더 자세히 살펴보면 만약 어떠한 데이터가 Snowflake 안으로 들어왔을 때 Virtual Warehouse마다 작업을 분담할 수 있게 된다.

예를 들면 데이터 적재(Load)만 담당하게 되는 Virtual Warehouse, 데이터 분석 및 시각화만(BI/Visualization) 담당하게 되는 Virtual Warehouse 등으로 워크로드를 완벽하게 분리해서 특정 작업을 할당하면 리소스 경쟁도 없어지게 된다. 결과적으로 Virtual Warehouse는 다른 Virtual Warehouse의 성능에 영향을 미치지 않게 된다.
2. Cache & Size
쿼리를 처리하는데 필요한 컴퓨팅 리소스는 쿼리의 크기와 복잡성에 따라 다르다. 쿼리가 복잡해질수록 더 큰 Virtual Warehouse가 필요하게 된다. 실행 중인 각 Warehouse는 쿼리가 Warehouse에서 처리될 때 엑세스 되는 테이블 데이터의 캐시를 보유하고 있다. 이렇게 되면 동일한 쿼리 작업을 수행할 때 테이블에서 데이터를 읽는 것이 아닌 캐시에서 읽을 수 있기 때문에 후속 쿼리의 성능이 향상된다. 이러한 캐시의 크기는 Warehouse의 컴퓨팅 리소스에 의해 결정된다. (Warehouse의 크기가 클수록 Warehouse의 컴퓨팅 리소스가 더 많다)
Snowflake Cache Layers
- 결과 캐시 : 지난 24시간 동안 실행 된 모든 쿼리의 결과를 저장. 이들은 Virtual Warehouse에서 사용할 수 있으므로 한 사용자에게 반환된 쿼리 결과는 기본 데이터가 변경되지 않은 경우 동일한 쿼리를 실행하는 시스템의 다른 모든 사용자가 사용 가능
- 로컬 디스크 캐시 : SQL 쿼리에서 사용하는 데이터를 캐시하는 데 사용. 지정된 쿼리에 데이터가 필요할 때마다 원격 디스크 스토리지에서 검색되어 SSD 및 메모리에 캐시됨
- 원격 디스크 : 장기 스토리지를 보유. AWS의 경우 99.9%의 내구성을 의미하는 데이터의 복원력을 담당
Warehouse Size
Virtual Warehouse는 데이터를 테이블로 Load하는 것을 포함하여 쿼리와 모든 DML 작업에 필요하다. Warehouse는 언제든지 시작하고 중지할 수 있는데 Warehouse에서 수행하는 작업 유형에 따라 컴퓨팅 리소스가 더 많이 필요할 수도 있고 더 적게 필요할 수도 있다. 이러한 작업의 정도를 체크해서 작업을 수행하는 중에도 Warehouse의 크기를 조정할 수 있다.
Warehouse를 생성하면서 사이즈를 아래와 같이 설정할 수 있다.
CREATE OR REPLACE WAREHOUSE my_wh WITH WAREHOUSE_SIZE = 'LARGE' -- Default = XSMALL
| Warehouse Size | Credits / Hour | Credits / Second |
| X-Small | 1 | 0.0003 |
| Small | 2 | 0.0006 |
| Medium | 4 | 0.0011 |
| Large | 8 | 0.0022 |
| X-Large | 16 | 0.0044 |
| 2X-Large | 32 | 0.0089 |
| 3X-Large | 64 | 0.0178 |
| 4X-Large | 128 | 0.0356 |
| 5X-Large | 256 | 0.0711 |
| 6X-Large | 512 | 0.1422 |
위의 표처럼 Warehouse의 크기는 티셔츠 사이징 방식이며 초 단위로 비용이 청구된다. 일반적으로 Warehouse가 클수록 쿼리를 처리하는데 사용할 수 있는 컴퓨팅 리소스가 더 많기 때문에 쿼리 성능은 Warehouse 크기에 따라 확장된다. (데이터 로드 성능이 항상 향상되는 것은 아님. 데이터 로드 성능은 Warehouse 크기보다 로드되는 파일의 수와 크기에 더 많은 영향을 받음) 따라서 Warehouse에서 처리하는 쿼리가 느리게 실행되는 경우 언제든지 Warehouse의 크기를 조정해서 더 많은 컴퓨팅 리소스를 프로비저닝할 수 있다. 또한 Snowflake는 기본적으로 처리할 쿼리가 없을 경우 Warehouse를 자동으로 일시 중단하거나 재개하는 기능을 지원하기 때문에 각 워크로드에 맞게 Warehouse 사용을 모니터링 및 자동화할 수 있고 이를 통해 사용자는 사용한 만큼만 과금을 지불할 수 있게 된다.
3. Scale Up vs Scale Out vs Scale Across
Snowflake는 Warehouse를 확장하는 세 가지 방법을 제공한다.
Scale Up

Scale Up은 기존 Warehouse의 컴퓨팅 성능을 업그레이드 하는 것이다. 이는 쿼리 성능을 개선하는 것으로 다운타임 없는 Scale Up/Down이 가능하고 클러스터에 노드를 추가하는 방식으로 성능을 개선한다. 이를 활용하면 아래처럼 동일한 작업이지만 Warehouse의 크기를 조정하여 더 빠르게 ETL 작업을 수행하는 것을 볼 수 있다.

Scale Out

Scale Out은 기존 Warehouse에 더 많은 클러스터를 추가하는 것이다. 이는 동일한 Warehouse에서 실행 중인 동시 쿼리가 많은 경우 도움이 된다. Scale Out으로 대기 중인 쿼리가 새로 프로비저닝 된 클러스터에서 실행될 수 있다.
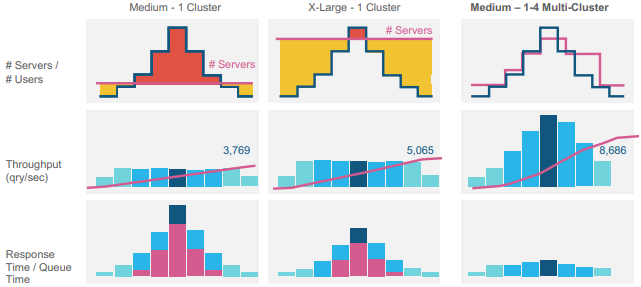
클러스터의 개수가 늘어남에 따라 실행환경을 과도/과소하게 프로비저닝하지 않고 요청에 맞게 자동으로 조정하고 처리량도 최대로 제공하는 것을 볼 수 있다. 또한 작업이 과하게 몰리는 피크 타임에도 일관된 성능을 제공할 수 있게 된다.
Scale Across

Scale Across는 다양한 워크로드가 혼용되는 환경에서 중요 워크로드의 실행 환경을 물리적으로 완벽하게 격리하여 워크로드 간에 자원 경합 현상을 해결한다. 위의 그림을 보면 기존 대다수 DBMS는 워크로드가 몰리는 경합 시간대에서 성능 저하가 발생하는 것을 볼 수 있는데 Snowflake에서는 워크로드의 물리적 실행 환경을 격리시키고 분리된 실행 환경에서 동일한 작업을 처리하여 성능을 개선한다.
Virtual Warehouse에 대한 내용을 이곳에서 모두 담기엔 한계가 있으니 다음 링크를 통해 좀 더 자세하게 살펴보기 바란다.
'Snowflake' 카테고리의 다른 글
| [Snowflake] 5. Security & Governance (0) | 2023.06.09 |
|---|---|
| [Snowflake] 4. Service Layer (0) | 2023.06.09 |
| [Snowflake] 2. Storage Layer (1) | 2023.06.09 |
| [Snowflake] 1. Snowflake Overview and Architecture (0) | 2023.06.09 |
| Snowflake 프로젝트 사전 준비 - 2 (2) | 2023.05.23 |



