Snowflake 프로젝트 사전 준비 - 1에서는 자사 서버에 Airflow를 설치해보았다. 본 글에서는 Airflow Dags를 통해 RDBMS에서 데이터를 Extract하고 이를 Snowflake에서 Load하는 과정을 정리하려고 한다. 모든 과정을 DAG를 작성하여 처리하기 이전에 각 단계별로 기능 테스트를 시행한 후 최종적으로 DAG로 작성하여 처리할 예정이다.
RDBMS - MySQL
원천이 되는 RDBMS는 자사 서버에 설치되어 있는 MySQL을 사용했다. PoC 과정에서 Snowflake 크레딧 이슈로 인해 샘플 데이터를 RDBMS에 이관하여 테스트를 진행한 적이 있는데 그 데이터를 활용할 예정이다.
CSV 데이터 추출
먼저 적재 대상 테이블을 csv 파일로 추출한다.
SELECT *
FROM mydb.esauser
INTO OUTFILE '/root/test/esauser.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY '\"'
LINES TERMINATED BY '\n';위 과정에서 SQL Error [1290] [HY000]: The MySQL server is running with the --secure-file-priv option so it cannot execute this statement 에러가 발생하였는데 이는 보안 관련 에러로 특정 디렉토리 이외에는 파일 쓰기가 금지되어 있을 경우 위의 에러가 발생한다. 해결방법은 두 가지로 해당 특정 디렉토리만 이용하거나 모든 디렉토리를 이용할 수 있도록 위의 보안 옵션을 해제하는 것이다.
1. 특정 디렉토리 확인
mysql> select @@GLOBAL.secure_file_priv;
+---------------------------+
| @@GLOBAL.secure_file_priv |
+---------------------------+
| /var/lib/mysql-files/ |
+---------------------------+
1 row in set (0.00 sec)위의 디렉토리에 outfile을 작성한다.
2. --secure-file-priv 무력화(MySQL 설정 변경)
vi /etc/my.cnf
-- 아래 항목 추가
secure-file-priv=""
-- MySQL 서버 재시작
systemctl restart mysqld본인은 기존 설정을 최대한 수정하지 않기 위해 1번 방법을 채택하여 해당 디렉토리에 CSV 파일을 추출하였다.
SELECT *
FROM mydb.esauser
INTO OUTFILE '/var/lib/mysql-files/esauser.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n';
정상적으로 추출되었다면 아래와 같이 해당 디렉토리에 CSV 파일이 있는 것을 확인할 수 있다.
(airflow) [root@pb6 dags]# ll /var/lib/mysql-files/
total 1080
-rw-r----- 1 mysql mysql 1105015 Apr 24 15:46 esauser.csv
Load To Snowflake
우선적으로 외부 저장소에서 Snowflake로 데이터를 로드할 때 사용되는 데이터 형식을 정의하는 개체인 `file_format ` 생성이 필요하다. `file_format`은 다양한 파일 형식을 지원하며 각 파일 형식의 구조와 구분자, 인코딩 등을 정의할 수 있다. MySQL에서 CSV로 데이터를 추출하였기 때문에 CSV 파일 형식으로 `file_format`을 생성한다.
CREATE OR REPLACE FILE FORMAT CSV_FORMAT
TYPE = CSV
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
FIELD_DELIMITER = ','
SKIP_HEADER=1
ESCAPE="\"
ESCAPE_UNENCLOSED_FIELD=NONE
NULL_IF = ('\\N', 'NULL', '');
Snowflake에서 데이터를 Load 하기 위해서는 데이터가 잠시 저장되는 장소인 Stage가 필요하다. AWS S3 등 외부 클라우드에서 데이터를 Load 할 때는 External Stage(외부 스테이지)를 생성하였지만 본 과정에서는 클라우드가 아닌 On-premise에서 데이터를 가져올 것이기 때문에 External Stage가 아닌 Internal Stage를 생성할 것이다. Stage를 생성하는 명령어는 다음과 같다.
-- External Stage 생성
CREATE OR REPLACE STAGE EXT_S3_STAGE
STORAGE_INTEGRATION = SNOWFLAKE_POC
URL='s3://path/s3/';
-- Internal Stage 생성
CREATE OR REPLACE STAGE MY_CSV_STAGE
FILE_FORMAT = CSV_FORMAT;
-- Stage 생성 확인
LIST @SNOWFLAKE_POC.PUBLIC.MY_CSV_STAGE;위의 과정을 마치면 정상적으로 Stage가 생성된 것을 확인할 수 있다. 현재는 Stage에 파일이 없기 때문에 아무것도 조회되지 않는 모습이다.


SnowSQL - PUT
로컬에 있는 파일을 Snowflake로 로드하기 위해서는 위에서 생성해 놓은 Stage에 데이터를 올리는 작업이 필요하다. 이를 위해서는 SnowSQL을 사용할 것이다. SnowSQL은 Snowflake에서 제공하는 CLI(Command Line Interface) 도구 중 하나로, 쉽고 편리한 방법으로 Snowflake 데이터 웨어하우스에 접속하여 데이터 관리 및 쿼리를 수행할 수 있도록 도와준다.
SnowSQL 설치
[root@pb6 dags]# wget https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowflake-snowsql-1.2.21-1.x86_64.rpm
[root@pb6 dags]# rpm -i snowflake-snowsql-1.2.21-1.x86_64.rpm
[root@pb6 dags]# snowsql -v
Version: 1.2.21SnowSQL 접속
아래와 같은 옵션을 사용하여 SnowSQL을 실행한다.
snowsql -a <account_name> -u <username> -d <databasename> -w <warehousename> -s <schemaname> -r <rolename> -p <password><account_name>에 Snowflake 계정 이름을 기재해주면 되는데 이 과정에서 제대로 된 계정명을 적어주어야 한다. 예를 들면`vt02663.ap-northeast-2.aws`과 같이 계정명.AWS 클라우드 리전명.aws으로 정확하게 적어주어야 한다. 위의 옵션 중 일부는 필수적인 옵션이며 나머지는 선택적인 옵션이다. 더 자세한 정보는 SnowSQL 설명서를 참조하기 바란다.
[root@pb6 ~]# snowsql -a vt02663.ap-northeast-2.aws -u admin -d SNOWFLAKE_POC -s public -r accountadmin -w WH_3
Password:
* SnowSQL * v1.2.21
Type SQL statements or !help
admin#WH_3@SNOWFLAKE_POC.PUBLIC>PUT
admin#WH_3@SNOWFLAKE_POC.PUBLIC>PUT file:///var/lib/mysql-files/esauser.csv @MY_CSV_STAGE;
+-------------+----------------+-------------+-------------+--------------------+--------------------+----------+---------+
| source | target | source_size | target_size | source_compression | target_compression | status | message |
|-------------+----------------+-------------+-------------+--------------------+--------------------+----------+---------|
| esauser.csv | esauser.csv.gz | 985612 | 161616 | NONE | GZIP | UPLOADED | |
+-------------+----------------+-------------+-------------+--------------------+--------------------+----------+---------+
1 Row(s) produced. Time Elapsed: 1.118s위처럼 `PUT` 명령어를 통해 로컬에 위치한 파일을 Snowflake Stage에 Upload 하였고 이는 Snowflake에서도 Stage 조회를 통해 확인할 수 있다.
LIST @SNOWFLAKE_POC.PUBLIC.MY_CSV_STAGE;

COPY INTO
이제 Stage에 업로드 되어 있는 파일을 `COPY INTO` 명령어를 통해 테이블로 로드한다. 이때 테이블은 미리 생성되어 있어야 하며 생성 과정(DDL)은 생략한다.
COPY INTO SNOWFLAKE_POC.PUBLIC.ESAUSER
FROM @SNOWFLAKE_POC.PUBLIC.MY_CSV_STAGE
FILE_FORMAT = (FORMAT_NAME = CSV_FORMAT);이후 해당 테이블을 조회하면 정상적으로 로드 된 것을 확인할 수 있다.
SELECT * FROM PUBLIC.ESAUSER;
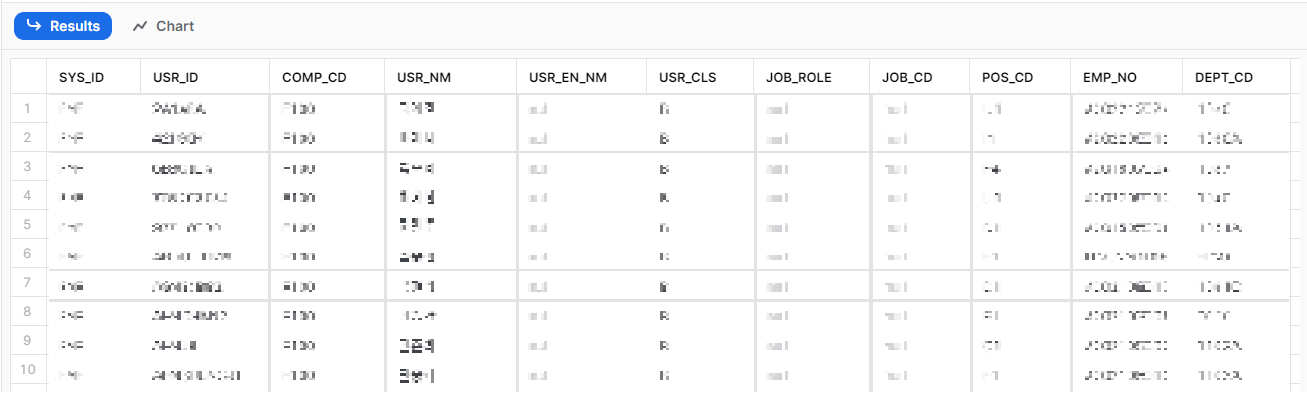
이렇게 MySQL에서 데이터를 추출하여 Snowflake로 로드하는 것까지 각 단계별로 살펴보았다. 이제 이 모든 과정을 Airflow DAG를 통해 한번에 처리해보도록 하자.
Airflow DAG
Airflow의 DAG는 'Directed Acyclic Graph'의 약자로 작업 흐름을 정의하는 데 사용되는 객체이다. DAG는 `PYTHON` 스크립트로 작성되며 작업 간의 의존성과 실행 순서를 정의할 수 있다. DAG의 작업(Task)는 작업을 실행하는데 필요한 모든 정보(코드, 인수, 환경 변수 등)가 포함된 'Operator' 객체이다.
MySQL Connection 생성
Airflow에서 MySQL에 쿼리하기 위해 Airflow에서 Connection 생성이 필요하다.
Airflow - [Admin] - [Connections] 메뉴 이동 및 [+] 눌러 새로운 Connection 생성

- Connection ID : Connection 이름
- Connection Type : MySQL
- Host : IP 주소
- Schema : Database
DAG 작성
먼저 Dag를 작성하기 위한 공간으로 dags 디렉토리를 생성한다. 이후 해당 디렉토리에 mysql2snowflake.py 파일을 작성해보자.
MySQL에 접근하여 쿼리를 수행하기 위해서는 `MySqlOperator`가 필요하다. `MySqlOperator`는 Airflow에서 제공하는 Operator중 하나로 MySQL에서 쿼리를 실행하는 데 사용된다. 해당 Operator를 설치하자.
pip3 install apache-airflow-providers-mysql해당 Operator를 설치하는 도중에 에러가 발생하였다.
MySQLdb/_mysql.c:46:20: fatal error: Python.h: No such file or directory
#include "Python.h"
이는 일반적으로 'MySQL-python' 라이브러리 설치 중에 발생하는 오류이다. 해당 오류를 해결하기 위해서는 `PYTHON` 개발 헤더 파일이 설치되어 있어야 한다. `PYTHON` 개발 헤더 파일은 일반적으로 `python-dev` 패키지 또는 `python-devel` 패키지에 포함되어 있다. 아래의 명령어로 해당 패키지를 설치해준다.
yum install python3-develMySQL Operator를 정상적으로 설치했다면 DAG에서는 아래와 같이 Import 한다.
from airflow.operators.mysql_operator import MySqlOperator
이제 DAG를 작성해보자. 아래는 esauser Table의 데이터를 CSV로 추출하는 Task를 가진 DAG이다.
from airflow.operators.mysql_operator import MySqlOperator
from airflow import DAG
with DAG( **dag_args) as dag:
#Export CSV From mysql
download_mysql = MySqlOperator(
task_id="mysql_task",
mysql_conn_id="mysql_phd",
sql="SELECT * FROM mydb.esauser INTO OUTFILE '/var/lib/mysql-files/esauser.csv' FIELDS TERMINATED BY ',' ENCLOSED BY '\"' LINES TERMINATED BY '\n';",
)- `download_mysql` : Task 이름
- `mysql_task` : Task id
- `mysql_conn_id` : Connection 이름
- `sql` : 수행하려는 쿼리(쿼리가 길어질 경우 execute.sql 등으로 저장하여 사용 가능)
다음은 추출한 CSV 파일을 Snowflake Stage에 PUT 하는 DAG를 작성해보자. 해당 과정은 스크립트를 실행하여 처리할 것이기 때문에 Bash 스크립트를 실행하여 작업을 수행하는 Bash Operator를 사용한다. 이는 Airflow에서 기본적으로 제공하는 Operator 중에 하나이므로 따로 설치할 필요는 없다.
from airflow.operators.bash_operator import BashOperator
from airflow import DAG
with DAG( **dag_args) as dag:
#Upload CSV To Snowflake Stage
upload_stage = BashOperator(
task_id="upload_stage",
# bash_command 문자열에 공백을 추가
# 공백 없으면 jinja2.exceptions.TemplateNotFound 에러발생
bash_command="$AIRFLOW_HOME/dags/bash_comm/upload_stage.sh ",
)위의 DAG를 작성할 때 유의할 점이 있다. 바로 수행할 스크립트 뒤에 공백을 추가해야 한다는 점이다. 해당 DAG를 작성한 후 Airflow에서 jinja2.exceptions.TemplateNotFound: 에러가 발생했었다. Bash Operator에서 템플릿을 사용하지 않았는데 TemplateNotFound 에러가 발생하는 경우이다. 이 경우는 스크립트 뒤에 공백을 추가하면 정상적으로 스크립트가 실행된다.
아래는 upload_stage.sh의 내용이다.
#! /bin/bash
# upload csv to snowflake stage
#-c : ~/.snowsql/config에 있는 connection 설정으로 연결
#-f : 해당 파일 실행
snowsql -c my_snowflake_conn -f /data2/airflow/dags/bash_comm/put.sqlsnowsql에 접속하는 동시에 PUT 작업을 수행하는 sql 파일을 실행하는 명령어인데 위에서 기존에 수행했던 명령어와는 약간의 차이가 있다.
기존 명령어 : `snowsql -a vt02663.ap-northeast-2.aws -u admin -d SNOWFLAKE_POC -s public -r accountadmin -w WH_3`
변경된 명령어 : `snowsql -c my_snowflake_conn -f /data2/airflow/dags/bash_comm/put.sql`
두 명령어의 차이는 접속하고자 하는 snowflake의 접속 정보를 따로 기재하지 않았다는 점이다. 이는 ~/.snowsql/config 파일에 따로 작성하여 해당 Connection을 불러오는 방식으로 더욱 간단한 명령어로 접속이 가능하다. Snowsql Connection 정보는 아래처럼 작성한다.
$ vi ~/.snowsql/config
[connections.my_snowflake_conn]
#Can be used in SnowSql as #connect example
accountname = vt02663.ap-northeast-2.aws
username = admin
password = **********
dbname = SNOWFLAKE_POC
schemaname = PUBLIC
warehousename = WH_3
rolename = ACCOUNTADMIN$ vi put.sql
PUT file:///var/lib/mysql-files/esauser.csv @MY_CSV_STAGE
마지막으로 Snowflake의 테이블로 파일을 Load 하는 DAG를 작성해보자.
from airflow.operators.bash_operator import BashOperator
from airflow import DAG
with DAG( **dag_args) as dag:
#Data Load From Snowflake Stage
copyinto_table = BashOperator(
task_id="copy_into_table",
bash_command="$AIRFLOW_HOME/dags/bash_comm/load_csv.sh ",
)위와 마찬가지로 Bash 스크립트를 실행하여 작업을 수행하였다. 아래는 load_csv.sh 스크립트의 내용이다.
#! /bin/bash
# copy into table from stage
#-c : ~/.snowsql/config에 있는 connection 설정으로 연결
#-f : 해당 파일 실행
snowsql -c my_snowflake_conn -f /data2/airflow/dags/bash_comm/copy.sql전 단계의 DAG 작성 방법과 같은 형식이기 때문에 자세한 설명은 생략하겠다. 아래는 copy.sql의 내용이다. Snowflake에서 수행했던 `COPY INTO` 명령어를 SnowSQL을 이용하여 외부에서 처리할 수 있다.
COPY INTO SNOWFLAKE_POC.PUBLIC.ESAUSER
FROM @SNOWFLAKE_POC.PUBLIC.MY_CSV_STAGE
FILE_FORMAT = (FORMAT_NAME = CSV_FORMAT);위에서 작성한 DAG들을 한번에 정리하면 아래와 같다.
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.mysql_operator import MySqlOperator
from airflow.operators.bash_operator import BashOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email': ['your-email@g.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag_args = dict(
dag_id="mysql2snowflake",
default_args=default_args,
description='',
schedule_interval=timedelta(minutes=50),
start_date=datetime(2022, 2, 1),
catchup=False,
tags=['EL TEST'],
)
with DAG( **dag_args) as dag:
#Export CSV From mysql
download_mysql = MySqlOperator(
task_id="mysql_task",
mysql_conn_id="mysql_phd",
sql="SELECT * FROM mydb.esauser INTO OUTFILE '/var/lib/mysql-files/esauser.csv' FIELDS TERMINATED BY ',' ENCLOSED BY '\"' LINES TERMINATED BY '\n';",
)
#Upload CSV To Snowflake Stage
upload_stage = BashOperator(
task_id="upload_stage",
# bash_command 문자열에 공백을 추가
# 공백 없으면 jinja2.exceptions.TemplateNotFound 에러발생
bash_command="$AIRFLOW_HOME/dags/bash_comm/upload_stage.sh ",
)
#Data Load From Snowflake Stage
copyinto_table = BashOperator(
task_id="copy_into_table",
bash_command="$AIRFLOW_HOME/dags/bash_comm/load_csv.sh ",
)
complete = BashOperator(
task_id='complete_bash',
bash_command='echo "COMPLETE~!"'
)
#Task 작업 수행 순서 지정
download_mysql >> upload_stage >> copyinto_table >> complete
위처럼 특정 Job을 수행하는 Task를 작성한 후 각 Task 간의 의존성과 작업 수행 순서를 지정할 수 있다. DAG가 정상적으로 작성되었다면 아래처럼 Web UI에서 id가 mysql2snowflake인 DAG를 확인할 수 있다.

DAG에서 정의한 Task가 작업 순서에 따라 나타나게 되고 이를 실행하면 아래처럼 각 Task가 정상적으로 수행되는 것을 확인할 수 있다.

'Snowflake' 카테고리의 다른 글
| [Snowflake] 3. Compute Layer (0) | 2023.06.09 |
|---|---|
| [Snowflake] 2. Storage Layer (1) | 2023.06.09 |
| [Snowflake] 1. Snowflake Overview and Architecture (0) | 2023.06.09 |
| Snowflake 프로젝트 사전 준비 -1 (0) | 2023.05.23 |
| Snowflake PoC (1) | 2023.05.23 |



