Compute Layer와 완전히 분리되어 있는 통합/단일 저장소 계층이다. Snowflake에서 사용되는 모든 데이터는 centralized되어 이 storage에 저장된다.
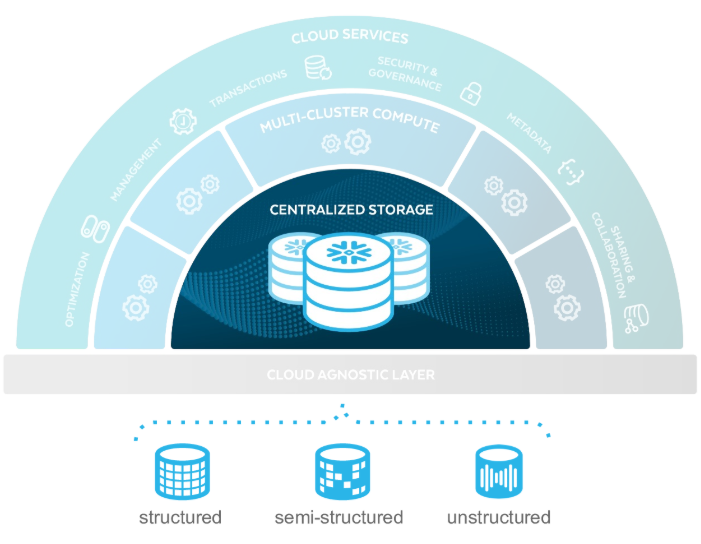
특징과 기능들을 하나씩 알아보자.
특징

통합된 데이터 저장소
- 정형, 반정형, 비정형 데이터를 위한 통합 저장소를 제공
- 분산되어 저장되지 않고, 통합 저장소 한 곳에만 저장되어 replica 생성 불필요
- 필요 시 데이터 볼륨이 On-Demand 방식으로 자동 확장
간편한 관리
- 최적화된 압축(80% 이상) 및 강력한 데이터 보안 지원
유연성 및 통합성 지원
- S3와 같은 클라우드 저장소, Iceberg와 같은 open source 및 On-Premise에 저장된 외부 데이터 직접 연결 지원
Stage & Table
Snowflake에는 Stage와 Table이 있다. 각각에 대한 설명은 아래와 같다.
Stage
Internal Stage
데이터 파일을 Snowflake 내부에 업로드할 때 생성한다. Table에 파일 내 데이터를 저장하기 전 임시 Stage 정도로 생각하면 된다.
External Stage
Snowflake 외부 저장소에 저장된 데이터 파일을 참조한다. 현재 아래 3가지 클라우드 저장소 서비스가 지원된다. Table에 파일 내 데이터를 저장하기 전 임시 Stage 정도로 생각하면 된다.
- Amazon S3 buckets
- Google Cloud Storage buckets
- Microsoft Azure containers
Internal Table
- Snowflake의 내부 스토리지에 데이터를 저장하는 테이블
- 데이터를 자주 변경해야 하는 경우나 짧은 시간에 대량의 데이터를 처리해야 하는 경우 유용
- 데이터에 대한 직접적인 제어를 제공
- 외부 스토리지에서 데이터를 로드하는 작업을 수행하지 않기 때문에 적은 양의 데이터를 처리할 때는 더 빠를 수 있
External Table
- 데이터 웨어하우스 외부의 데이터 소스에 대한 참조를 나타내는 메타데이터 객체
- 스노우플레이크 데이터 웨어하우스에 직접 저장되는 것이 아니라, 클라우드 스토리지나 외부 데이터베이스와 같은 외부 데이터 소스에 저장된 데이터를 참조하는 External Stage를 통해 메타데이터를 저장한다. 이 메타데이터를 통해 외부 저장소의 데이터를 가상 테이블로 보여주는 뷰 역할을 한다고 보면 된다.
- 데이터가 변경되지 않고 읽기 전용인 경우에 유용하다.
- 테이블 생성 및 삭제 시간이 빠름
- 데이터 용량 제한이 없음
- 스키마 변경 작업 없이도 데이터를 쉽게 공유 가능
- snowflake 외부에 저장된 데이터를 쿼리하기 때문에 internal table 보다 쿼리 속도가 느릴 수 있다. 이는 External Table을 기반으로 하는 Materalized View를 사용하여 쿼리 성능을 향상시킬 수 있다.
Snowflake Ingestion
외부 저장소나 서비스, 툴들을 통해 snowflake로 데이터를 어떻게 저장하는지 알아보자.

1. ETL Tools
Snowflake는 실제 프로젝트에서 자사가 native하게 지원하는 파트너사들의 툴들을 많이 이용하도록 권장한다. 여기서 native는 해당 툴들을 이용하여 Snowflake의 데이터 웨어하우스와 높은 호환성을 가져 쉽게 데이터를 읽고 쓸 수 있으며, 적재 프로세스를 더욱 빠르고 쉽게 수행할 수 있다는 의미이다. ETL Tools 관련 파트너사 관련 정보는 다음 링크를 참고하기 바란다.
2~3. External Cloud Storage
S3와 같은 외부 클라우드 저장소에서 snowflake로 데이터를 가져오는 방법은 Bulk Load 방식과 Continuous 방식이 있다.
Bulk Load
외부 클라우드 저장소의 데이터에 대한 Stage를 생성한 후 저장할 파일에 해당하는 Format을 생성하고 COPY INTO 명령어를 사용하여 snowflake storage로 Bulk Load 할 수 있다.
> CREATE STAGE my_external_stage
URL = 's3://my-bucket/my-path/'
> create or replace file format csv type='csv'
compression = 'auto' field_delimiter = ',' record_delimiter = '\n'
skip_header = 0 field_optionally_enclosed_by = '\042' trim_space = false
error_on_column_count_mismatch = false escape = 'none' escape_unenclosed_field = '\134'
date_format = 'auto' timestamp_format = 'auto' null_if = ('') comment = 'file format for ingesting data to snowflake';
> copy into trips from @my_external_stage file_format=csv pattern= '.*csv.*';
아래 그림과 같이 외부 클라우드 저장소로부터 데이터를 로드, 언로드 할 수 있다.
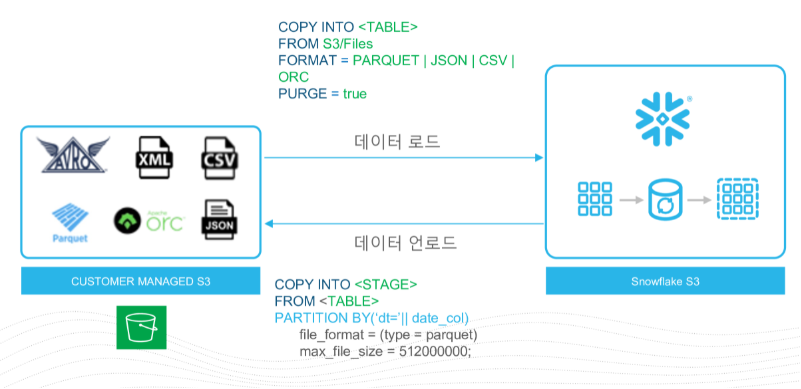
Continuous
S3는 데이터의 지속적 처리를 위해 이벤트 알림 옵션을 사용하여 새로운 데이터가 들어오면 SQS에 notification을 남길 수 있는데, 이 notification을 바라보며 Snowpipe service로 데이터를 snowflake 적재 가능하다.

Snowpipe에 대한 설명은 Service Layer 장에서 자세히 다룰 것이다.
4. Kafka Connector
Kafka Connector는 Apache Kafka와 Snowflake 간의 데이터 전송을 가능하게 해주는 도구로, 파트너사의 ETL Tool 다음으로 권장하는 Connector 이다.
Kafka Connector는 테이블 이름과 스키마, 데이터 타입, 인덱스 등의 구성 정보를 지정할 수 있다. 이를 통해 사용자는 Snowflake 테이블을 자신의 요구에 맞게 구성할 수 있으며, 이를 통해 데이터 처리 속도와 효율성을 향상시킬 수 있다.
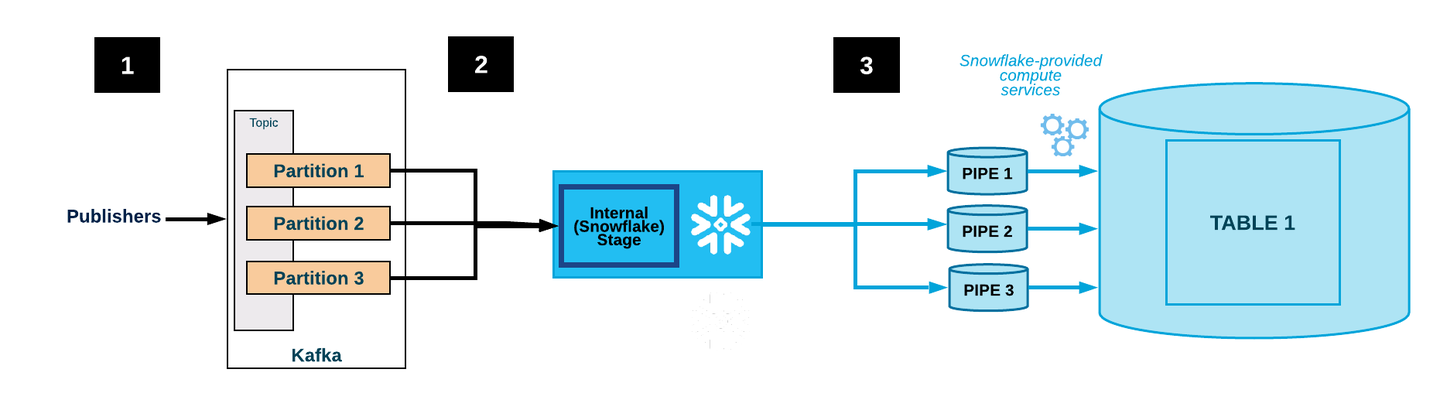
위 그림에 대한 과정은 다음과 같다.
- 어플리케이션이 JSON 또는 Avro 레코드를 Kafka 클러스터에 게시한다. 레코드는 1개 이상의 파티션으로 분할된다.
- 데이터 수집 : Kafka Connector는 Kafka 토픽에서 데이터를 수집한다.파일 적재 : 버퍼가 가득 차거나 로딩 작업이 트리거되면, 버퍼에 있는 데이터는 파일로 Topic과 Partition별로 생성된 Internal Stage에 적재된다.
- 데이터 버퍼링 : 수집된 데이터는 버퍼링을 위해 일시적인 스토리지 영역에 저장된다. 이때, 버퍼의 크기는 사용자가 설정할 수 있으며, 기본값은 100MB이다.
- Internal Stage에 파일 데이터가 저장된 후, Topic과 Partition별로 Snowpipe가 생성되어 데이터를 Internal Stage에서 읽어와 Snowflake Storage에 적재한다.
- Kafka Connector는 Snowpipe를 모니터링 하여 파일 데이터가 테이블에 적재된 것을 확인한 후, Internal Stage의 파일 데이터를 삭제한다.
실패로 인해 데이터를 로드할 수 없는 경우, Kafka Connector는 파일을 Internal Stage로 이동하고 오류 메시지를 생성한다. - 커넥터는 2~4 단계를 반복한다.
5~8. Other Connector
각 서비스들은 해당 서비스에 대한 Snowflake Connector를 이용하여 데이터를 Snowflake Storage로 적재 가능하다.
Snowflake는 계속하여 각 서비스에 대한 Connector 지원을 넓혀가고 있다.
Data Loading In Snowflake Storage

Structured & Semi-structured data
Snowflake는 정형 데이터 뿐만 아니라 반정형 데이터 유형에 대해서도 최적화된 저장소를 지원한다.

정형 데이터
- 데이터 로드 시, 테이블 컬럼에 1:1 매핑하여 저장
- COPY INTO시, 자동으로 Snowflake 저장 형식에 맞게 변환됨
- 데이터를 로드하는 시점에 자동으로 메타정보와 통계 데이터를 생성
아래와 같은 테이블이 있다면
| product | cost | quantity | code |
| Apple | 1105 | 250 | FIH-2316 |
| Samsung | 980 | 202 | IHO-6912 |
| LG | 780 | 600 | WHQ-6090 |
조회 쿼리는 다음과 같다.
SELECT product, cost, quantity, code FROM product_info;반정형 데이터
- 다양한 datatype 지원 (JSON, Avro, Parquet, ORC, XML, Delta Lake, CSV, TSV, protobuf)
- 원본 데이터(Document)를 그대로 저장
- SQL로 처리가능 : Dot notation
아래와 같은 JSON 파일이 저장되어 있다면
> SELECT * FROM sample_table;
+-----------------------------------------+
|SRC |
|-----------------------------------------|
|{ |
| "users": [ |
| { |
| "city": "Seoul", |
| "first_name": "Kitae", |
| "gender": "male", |
| "job": "data engineer", |
| "last_name": "Kim" |
| }, |
| { |
| "city": "Seoul", |
| "first_name": "Heedong", |
| "gender": "male", |
| "job": "data engineer", |
| "last_name": "Park" |
| } |
| ] |
|} |
+-----------------------------------------+
JSON의 각 key 이름을 통해 value에 대한 접근이 가능하다.
조회 쿼리는 다음과 같다.
> SELECT
value:first_name::STRING AS first_name
FROM sample_table
, LATERAL FLATTEN( INPUT => SRC:users );
+--------------------------+
| value:first_name::STRING |
|--------------------------|
| Kitae |
| Heedong |
+--------------------------+Micro-Partitions
Snowflake에서 대용량 테이블에 대한 쿼리 효율성을 개선하기 위한 방법으로 Micro-Partition이라는 강력하고 고유한 기능을 제공한다. Micro-Partition은 정적 파티션에서 제공했던 장점을 그대로 활용하면서 동시에 단점을 해결한 Snowflake 만의 고유한 기능이다.
아키텍쳐로 데이터가 적재되어 Micro-Partition으로 분할, 압축되어 저장되는 방식은 아래 그림과 같다.

Snowflake는 데이터를 저장할 때 컬럼 기반 형태로 저장하며, 이 컬럼 기반 형태로 저장된 데이터를 분할하여 아래 그림과 같이 저장한다. 이 분할된 각각의 작은 단위를 Micro-Partition 이라고 한다.

Snowflake에서 데이터는 기본적으로 클러스터링 키로 설정된 컬럼을 기준으로 50MB ~ 500MB 크기의 데이터로 분할된 후, 일반적으로 16MB정도로 압축을 하여 Micro-Partition 단위로 저장한다. 압축 시에는 데이터 형식에 따라 GZIP, LZO, ZSTD와 같은 각 데이터에 맞는 압축 알고리즘을 사용한다.
Clustering Key
Clustering key 생성
테이블을 생성할 때 클러스터링 키를 아래와 같이 설정할 수 있다.
CREATE TABLE my_table (
column1 INTEGER,
column2 STRING,
column3 DATE
)
CLUSTER BY (column1, column2);column1과 column2가 클러스터링 키로 지정된 것이다.
해당 테이블에 대한 정보는 아래 쿼리로 볼 수 있다.
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = 'MY_TABLE';Clustering key 선택 전략
클러스터링 키 선택 전략은 아래와 같다.
- 키당 최대 3~4개의 컬럼을 권장한다. 그 이상 추가하면 클러스터링 키의 이점보다 비용이 더 많이 증가하는 경향이 있을 수 있다.
- 컬럼 중 활발하게 사용되는 컬럼을 클러스터링 키로 선택한다. 하지만 컬럼의 cardinality가 너무 높으면(중복도가 너무 낮으면) 클러스터링을 유지 관리하는데 더 많은 비용이 들어간다. cardinality가 너무 낮은(중복도가 너무 높은) 컬럼(ex: 성별)은 클러스터링 키로 적합한 쿼리 성능을 낼 수 없다.
- 테이블에 대한 다중 클러스터링 키를 정의하는 경우, 지정하는 컬럼의 순서가 중요하다. 클러스터링 키의 순서는 cardinality가 낮은 컬럼부터 높은 컬럼으로 정렬할 것을 권장한다. cardinality가 높은 컬럼을 앞에 배치할 경우, 후자열에 대한 클러스터링 효율성이 감소하기 때문이다.
Pruning
Snowflake에서 Pruning은 쿼리 성능을 최적화하는 기술 중 하나로, 쿼리 실행 시 필요한 데이터만 검색하도록 선택적으로 데이터를 가져오는 것을 말한다. 이를 통해 쿼리 처리 속도를 향상시킬 수 있으며, 불필요한 데이터를 가져오고 처리하는 데 필요한 비용을 줄일 수 있다.

위와 같은 데이터가 있다고 하자. 위 테이블의 클러스터링 키는 ID와 Date 이다. Pruning은 다음과 같은 방법으로 수행된다.
- where 조건절에 클러스터링 키인 date를 사용하여 11/2일은 날짜의 데이터를 조회한다.
- Service Layer는 각 Micro-partitions의 클러스터링 키에 대한 Min/Max 값을 가지고 있다. 이 Min/Max 값을 사용하여 11/2일에 해당하는 데이터가 있는 Micro-partitions만 검색한다. 위 그림에서는 4개의 Micro-partitions 중 2개만 해당되므로 2개만 스캔한다.
- 스캔한 2개의 Micro-partitions에서 데이터를 가져와 쿼리 결과를 생성한다.
여기서 주의할 점은, Pruning은 클러스터링 키를 사용하여 데이터를 필터링하는 기능이기 때문에, 클러스터링 키가 아닌 컬럼을 WHERE 조건에 사용하면 Pruning을 이용할 수 없다. 물론 WHERE 조건에 클러스터링 키를 사용하지 않아도 데이터베이스 엔진은 인덱스를 이용한 필터링 등 다른 최적화 기술을 이용하여 쿼리 실행 성능을 향상시킬 수 있다. 하지만 Pruning을 최대한 활용하려면 WHERE 조건에는 클러스터링 키를 사용하는 것이 좋다.
이처럼, Pruning은 조건절에서 제공된 조건을 기반으로 데이터를 필터링하고 필요한 데이터만 검색함으로써 쿼리 실행 속도를 향상시킨다. 이를 통해 사용자는 별도로 Pruning을 구현할 필요 없이 최적화된 쿼리 실행을 쉽게 수행할 수 있다.
Micro-Partition의 장점
이 Micro-Partition 단위로 저장함으로 인해 가져올 수 있는 장점들은 아래와 같다.
- 빠른 쿼리 처리 : Micro-Partition은 데이터를 빠르게 쿼리할 수 있도록 최적화된 작은 단위의 데이터 블록이다. 이를 통해 쿼리 처리 속도가 빨라지며, 대용량 데이터셋도 빠르게 처리할 수 있다.
- 효율적인 스토리지 관리 : Micro-Partition은 작은 단위의 데이터 블록으로 분할되어 저장된다. 이를 통해 작은 파일이 생성되지 않도록 하여 스토리지 사용량을 효율적으로 관리할 수 있다.
- 스케일 아웃 : Micro-Partition은 수평 스케일 아웃에 적합하다. 이를 통해 데이터 처리 작업을 병렬로 처리하면서 처리 성능을 향상시킬 수 있다.
- 데이터 관리의 용이성 : Micro-Partition을 사용하면 데이터를 논리적으로 분리하여 저장할 수 있다. 이를 통해 데이터 관리가 용이해지며, 데이터셋의 일부를 수정하거나 삭제하는 등의 작업을 보다 쉽게 수행할 수 있다.
- 비용 효율성 : Micro-Partition은 필요한 만큼만 스토리지를 사용하도록 최적화되어 있다. 이를 통해 비용을 절감할 수 있으며, 필요에 따라 스토리지 용량을 확장할 수 있다.
이 Micro-Partition에 관련된 Auto-Clustering, Re-Clustering에 대한 Speed Up부분은 Service Layer 장에서 더 자세히 다룰 것이다.
Schema Detection & Evolution
Snowflake에서 Schema Detection & Evolution은 데이터베이스 스키마 변경 시에 자동으로 스키마 변경을 감지하고, 기존 테이블과 호환되도록 스키마를 업데이트하는 기능이다. 이를 통해 개발자는 스키마 변경으로 인한 데이터 무결성 문제에 대한 걱정 없이 스키마를 자유롭게 수정할 수 있다.

Snowflake에서 Schema Detection & Evolution은 다음과 같은 방식으로 작동한다.
- 스키마 변경 감지
- 데이터베이스에 새로운 스키마 변경이 발생하면 Snowflake는 자동으로 이를 감지한다.
- 호환성 분석
- Snowflake는 변경된 스키마가 기존 테이블과 호환되는지 분석한다. 이 때, 호환성 분석을 위해 스키마 변경 내역과 테이블 스키마 정보가 비교된다.
- 스키마 업데이트
- 호환성 분석이 완료되면, Snowflake는 변경된 스키마를 기존 테이블과 호환되도록 자동으로 업데이트한다. 이 때, 기존 데이터를 유지한 채로 스키마를 업데이트하므로, 데이터 무결성이 보장된다.
- 사용자 알림
- 스키마 변경이 완료되면, Snowflake는 해당 스키마를 사용하는 모든 사용자에게 변경 내역을 알린다. 이를 통해 개발자는 스키마 변경이 적용되었는지 확인하고, 필요한 경우에 대한 추가적인 작업을 수행할 수 있다.
Schema Detection & Evolution은 데이터베이스 스키마 변경을 더욱 유연하게 관리할 수 있도록 도와준다. 이를 통해 개발자는 데이터베이스를 더욱 쉽게 유지보수할 수 있으며, 데이터 무결성 문제를 줄일 수 있다.
Time Travel & Fail Safe
데이터 저장소에서 Backup이나 Snapshot은 매우 중요하고 반드시 해야하는 작업 중 하나이다. Snowflake에서는 사용자가 이러한 작업을 신경 쓰지 않아도 Snowflake 내부에서 자동으로 데이터의 이력을 보존하고, 이전 시점의 데이터를 쉽게 복구하거나 비교할 수 있도록 하는 Time Travel 기능을 제공한다.
Time Travel의 표준 보존 기간은 1일이고 자동으로 활성화 되어 있다. Snowflake Enterprise Edition 이상의 경우 이 설정을 변경하여 최대 90일까지 더 오래된 데이터를 보존할 수 있다.
그 이후 시스템 오류 및 기타 보안 위반 이벤트가 발생한 경우 데이터를 복구할 수 있는 Fail Safe 기간은 7일을 제공하며, 따로 구성을 불가하다. Fail Safe를 통한 데이터 복구는 완료하는데 몇 시간에서 며칠이 걸릴 수 있다.
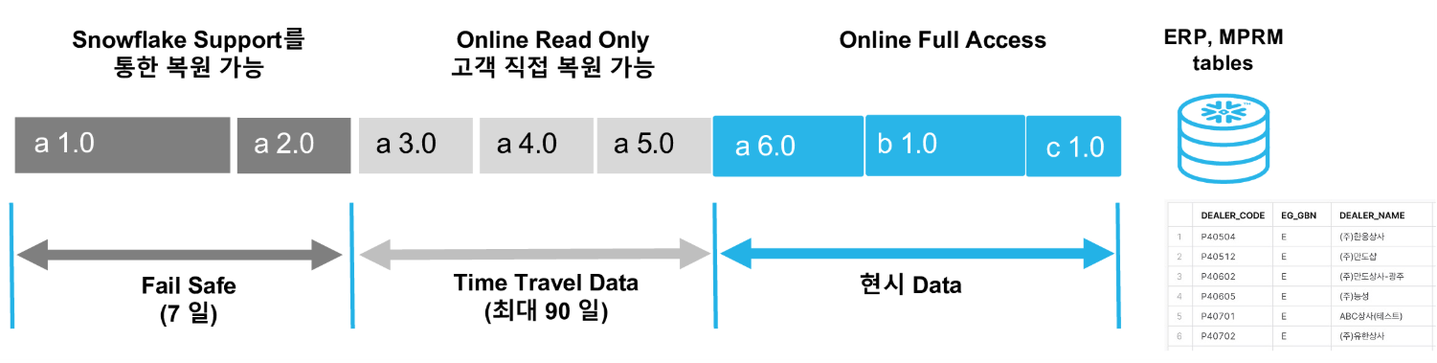
위 그림에서는 Time Travel 기간을 90일로 설정했다. 총 90일 기간동안의 데이터를 Time Travel을 사용하여 복구 가능하며, Fail-Safe 기능으로 90일동안의 이전 데이터들을 90일 이후에 7일동안 추가로 복구할 수 있다. 단 Fail Safe 기간엔 고객이 직접 복원이 불가능하고, Snowflake의 데이터 복구 전문가에 의해 복원이 가능하다.
따라서, Fail-Safe는 데이터 손실을 최소화하고 데이터의 안전성을 보장하기 위한 최후의 보호 기능이며, Time Travel과 같이 과거 데이터에 액세스하기 위한 목적의 기능이 아니며, 사용자가 데이터를 복구하는 것은 아니라는 점을 명심해야 한다.
Time Travel 관련 명령어
UNDROP
Time Travel은 세 가지 방식으로 이전 데이터를 조회할 수 있다.
1. 기간(Time Travel Duration)을 지정하여 데이터 조회
- 이전 시점으로 돌아가기 위해 쿼리를 수행하는 시점의 기간을 지정하여 조회하는 방식
- 예를 들어, 현재 시간으로부터 5분 전의 데이터를 조회하려면 TIME_TRAVEL 함수를 사용하여 다음과 같이 쿼리를 작성할 수 있다.
> SELECT * FROM my_table AT(OFFSET => -60*5);
2. 특정 시점(Time Travel Timestamp)의 데이터 조회
- 지정한 시점에 저장된 데이터를 직접 조회하는 방식
> SELECT * FROM my_table AT(TIMESTAMP => 'Fri, 01 May 2015 16:20:00 -0700'::timestamp_tz);
3. 특정 Statement ID로 데이터 조회
- 과거 데이터의 Statement ID로 데이터를 조회하는 방식
Snowflake는 각각의 실행했던 쿼리에 고유한 Statement ID를 부여하며, 이를 사용하여 해당 쿼리의 실행 상태 및 결과를 추적할 수 있다. 아래 명령어로 전에 실행했던 쿼리들의 ID를 조회할 수 있다.
이렇게 불러온 이전 데이터를 복제하거나 변경 내용 분석 등의 용도로 사용할 수 있다.
> select query_id, query_text, start_time
from table(information_schema.query_history_by_session())
order by start_time desc;여기서 나온 query_id로 해당 쿼리문을 실행하기 전 상태의 데이터를 조회할 수 있다.
> SELECT * FROM my_table BEFORE(STATEMENT => '8e5d0ca9-005e-44e6-b858-a8f5b37c5726');Time Travel 기간 설정
계정, 데이터베이스, 스키마 및 테이블의 보존 기간을 변경하려면 ALTER <object> 명령을 사용하면 된다. 상위 객체의 보존 기간을 변경하면 명시적으로 설정되지 않은 모든 하위 수준의 객체의 값이 변경된다. 예로 가장 높은 계정 수준에서의 보존 기간을 변경하면 명시적 보존 기간이 없는 모든 데이터베이스, 스키마 및 테이블이 자동으로 계정의 보존 기간을 상속받는다. 아래는 테이블의 보존 기간을 생성 및 변경하는 쿼리이다.
> CREATE TABLE mytable(col1 NUMBER, col2 DATE) DATA_RETENTION_TIME_IN_DAYS=90;
> ALTER TABLE mytable SET DATA_RETENTION_TIME_IN_DAYS=30;
이러한 Time Travel 기능을 사용하면, 데이터를 변경한 사용자, 변경 내용, 변경 시간 등의 이력을 추적할 수 있다. 이를 통해 데이터 무결성 유지 및 데이터 분석에 있어서 과거 데이터를 쉽게 비교하거나 추적할 수 있다. 또한, Time Travel 기능은 이전 시점의 데이터는 마이크로 파티션 내부에 현재 시점의 데이터와 함께 저장되므로, 기본 설정인 1일로 사용 시 별도의 저장 공간을 필요로 하지 않으며, 비용을 추가로 지불할 필요가 없다.
과금
Time Travel에 대한 과금은 이전 상태의 데이터를 얼마나 오래 유지하느냐에 따라 달라진다.
Snowflake에서는 Time Travel에 대한 보관 기간을 정할 수 있으며, 이 보관 기간에 따라 과금이 결정된다. 기본적으로 Snowflake은 데이터 웨어하우스에서 생성된 모든 데이터를 1일간 보관한다. 따라서, 1일 이내의 Time Travel에 대해서는 추가적인 비용이 발생하지 않는다.
그러나 1일 이상의 Time Travel을 사용하려면 Snowflake에서 이전 데이터를 저장하기 위한 추가 비용이 발생한다. Snowflake는 업데이트되거나 삭제된 데이터를 복원하는 데 필요한 정보만을 유지하여 과거 데이터 복구에 필요한 스토리지 공간을 최소화 한다. 테이블이 삭제되는 경우에만 전체 복사본을 생성하여 유지한다. 이때 발생하는 요금은 데이터가 변경된 시점부터 24시간마다 계산된다.
Zero-Copy Cloning
Snowflake의 zero copy cloning은 데이터베이스 복제를 보다 효율적으로 수행할 수 있도록 해주는 중요한 기능이다. 이 기능은 기존의 데이터를 복제할 때 복제할 데이터를 실제로 복사하지 않고, 데이터에 대한 참조만 생성하여 데이터를 복제한다. 이로 인해 데이터의 복제 속도가 빨라지고 디스크 공간을 절약할 수 있다.
기존에는 DEV 환경 생성을 위해 기존의 데이터를 복제하면 복제할 데이터를 읽어서 새로운 위치에 다시 쓰는 과정을 거치기 때문에 시간과 디스크 공간이 소요되었다. 그러나 zero copy cloning은 새로운 데이터를 생성하지 않고, 기존 데이터에 대한 참조만 생성하기 때문에 속도와 공간면에서 이점을 가지게 된다.
또한, 데이터베이스에서 zero copy cloning을 사용하면 여러 클론을 생성할 수 있다. 클론은 원본 데이터와 동일한 데이터를 참조하지만, 각각 다른 쿼리에 대한 응답으로 사용될 수 있다. 따라서 클론은 원본 데이터를 수정하지 않고, 원본 데이터를 사용하는 애플리케이션과 동시에 사용될 수 있다.
DEV 환경 구축
다음 그림은 원본 데이터 XXX를 사용하여 User2가 DEV 환경을 구축하는 것을 표현한 것이다. 생성, 조회, 변경의 경우에 대해 알아보자.

클론 테이블 생성
Snowflake에서 클론 테이블을 생성하는 방법은 간단하다. 원본 테이블을 선택하고, CREATE TABLE 명령어를 사용하여 새로운 테이블을 생성하면서 CLONE 키워드를 사용하면 된다.
> CREATE OR REPLACE TABLE ZZZ CLONE XXX;이렇게 생성된 클론 테이블은 원본 테이블과 동일한 스키마를 가지며, 데이터도 원본 테이블과 동일하다.
클론 테이블의 데이터 조회
위 그림을 보면 원본 테이블인 XXX를 CREATE 문을 사용하여 클론 테이블인 ZZZ를 생성하였다. 만일 여기서 SELECT * FORM ZZZ; 쿼리문을 실행시키면 클론 테이블인 ZZZ에서 데이터를 가져오는 것처럼 보이지만, 실제로 데이터는 XXX에서 가져와 결과를 보여준다. ZZZ 테이블은 XXX 테이블에 대한 참조만 가지고 있기 때문이다. 하지만 clone 이후에 변경분이 있다면, 해당 변경분은 원본 테이블과는 독립적이기 때문에 그 변경분을 적용한 데이터를 보여준다.
클론 테이블의 데이터 추가 및 변경
클론 테이블에 데이터 및 스키마를 추가 및 변경하는 방법은 일반적인 테이블에 데이터를 추가하는 것과 동일하다.
> INSERT INTO ZZZ (col1, col2, col3) VALUES (value1, value2, value3);
> UPDATE ZZZ SET col1 = 'a';
> ALTER TABLE ZZZ DROP COLUMN col1;이렇게 추가 및 변경된 데이터 및 스키마는 새로운 스토리지 클론 테이블에만 저장되며, 원본 테이블에는 영향을 주지 않는다.
장점
정리하자면 Zero-Copy Clones 기능의 장점은 아래와 같다.
- 동일한 파일을 가리키는 메타데이터 Pointer(참조) 복사
- 빠른 데이터 복사로 CREATE ... CLONE ...쿼리 하나로 개발 환경 구축
- Cloning에 대한 추가 스토리지 불필요
- 추가 및 변경 데이터에 대해서만 저장소 과금 발생
'Snowflake' 카테고리의 다른 글
| [Snowflake] 4. Service Layer (0) | 2023.06.09 |
|---|---|
| [Snowflake] 3. Compute Layer (1) | 2023.06.09 |
| [Snowflake] 1. Snowflake Overview and Architecture (0) | 2023.06.09 |
| Snowflake 프로젝트 사전 준비 - 2 (2) | 2023.05.23 |
| Snowflake 프로젝트 사전 준비 -1 (0) | 2023.05.23 |



