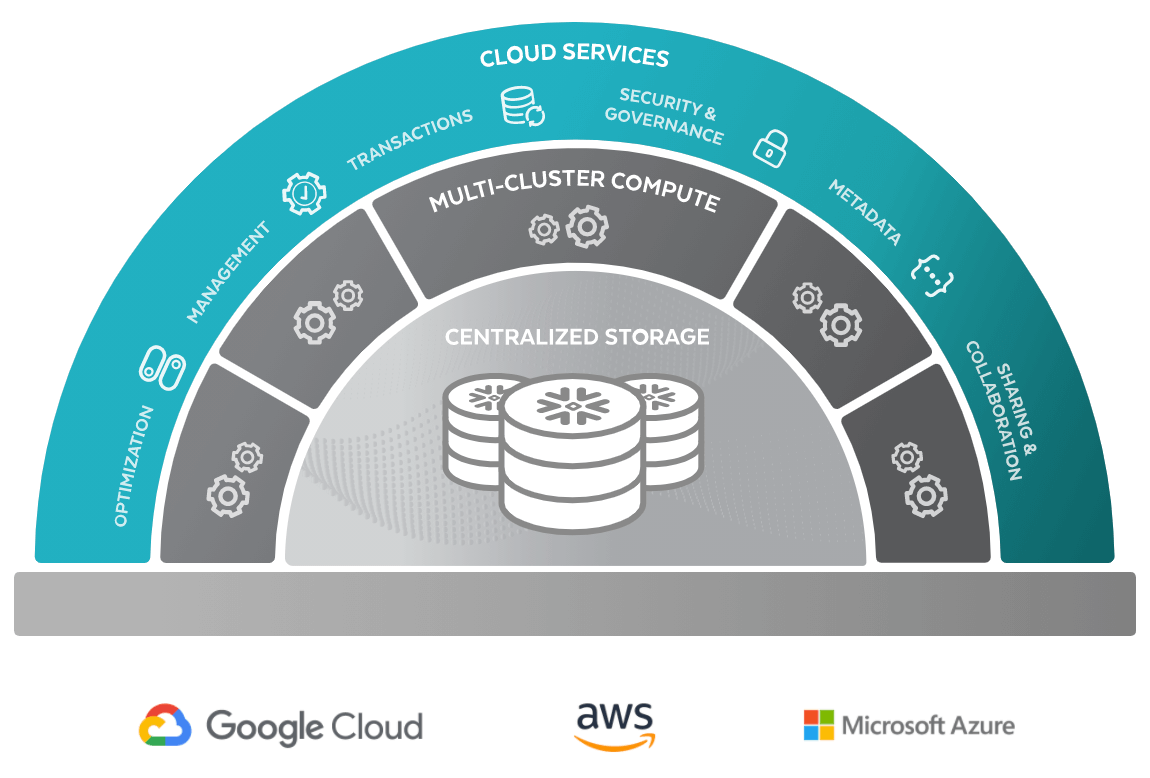
[Snowflake] 4. Service Layer
Intelligence Infrastructure인 완전 관리형 서비스로서 자동화를 통해 위험을 줄이고 효율성을 개선하여 사용자가 중요한 일에 더욱 집중할 수 있도록 도와주는 계층이다. Cloud Service 계층에는 인증, 보안, 데이터 관리 및 쿼리 최적화와 같이 Snowflake 전체에서 조정하는 모든 작업이 포함된다. Cloud Service 계층은 서로 다른 가용 영역에서 작동하고 액세스 및 사용 가능성이 높은 정보를 사용하는 상태 비저장 컴퓨팅 리소스이다. DDL 및 DML과 같은 데이터 작업을 위한 SQL 클라이언트 인터페이스를 제공한다.
캐싱 자동화
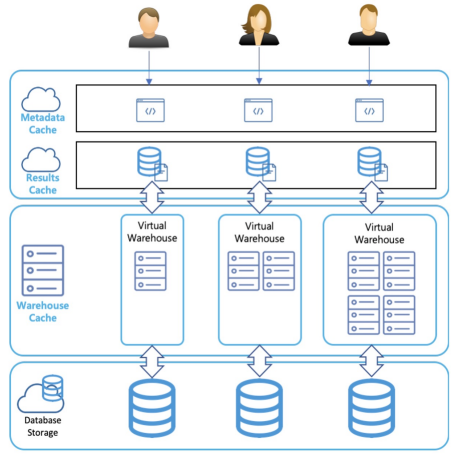
쿼리를 처리하는데 필요한 컴퓨팅 리소스는 쿼리의 크기와 복잡성에 따라 다르다. 쿼리가 복잡해질수록 더 큰 Virtual Warehouse가 필요하게 된다. 실행 중인 각 Warehouse는 쿼리가 Warehouse에서 처리될 때 액세스 되는 테이블 데이터의 캐시를 보유하고 있다. 이렇게 되면 동일한 쿼리 작업을 수행할 때 테이블에서 데이터를 읽는 것이 아닌 캐시에서 읽을 수 있기 때문에 후속 쿼리의 성능이 향상된다. 이러한 캐시의 크기는 Warehouse의 컴퓨팅 리소스에 의해 결정된다.
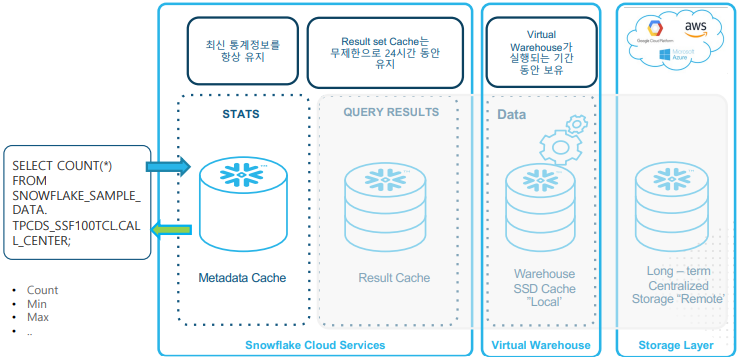
위에서 설명한 쿼리 처리 방식을 도식화하면 아래와 같다. 메타데이터 캐시는 쿼리에 대한 최신 통계정보(Metadata)를 유지하고 있고 이에 대한 결과를 결과 캐시가 최대 24시간 동안 유지하고 있다. 이후 데이터 변경이 발생하지 않은 테이블에 대해 동일 쿼리가 발생하면 테이블에서 데이터를 읽는 것이 아닌 캐시에서 읽을 수 있기 때문에 쿼리 시간을 크게 줄이는 등 후속 쿼리의 성능이 향상된다.
새로운 사용자의 쿼리를 수행하기 위해 Warehouse가 Storage Layer에 저장되어 있는 테이블에서 데이터를 읽어들이게 된다.
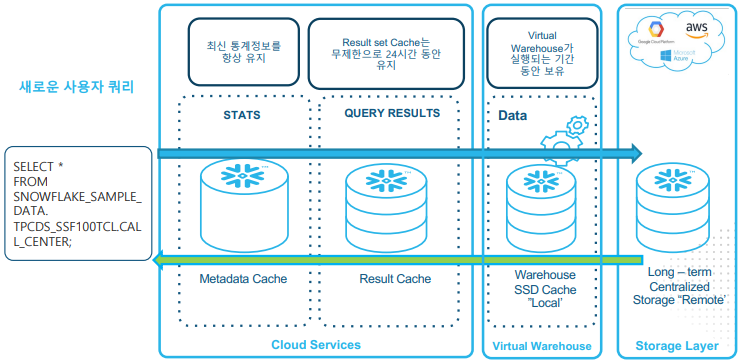
하지만 동일한 쿼리 수행 결과는 컴퓨팅 없이 캐싱된 결과셋을 반환하고 해당 결과값을 Result Cache가 24시간동안 가지고 있기 때문에 빠른 쿼리 결과를 가져올 수 있게 된다.
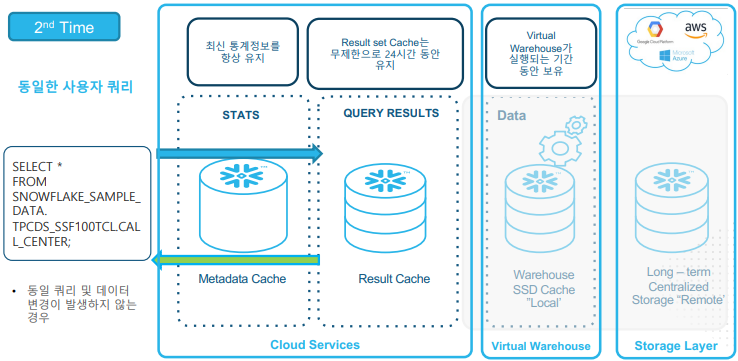
이후 변경된 쿼리를 수행할 때는 지정된 쿼리에 데이터가 필요할 때마다 원격 디스크 스토리지에서 검색되어 SSD 및 메모리에 캐시되어 원격 디스크 Read를 최소화 한다.

Elastic Performance
SPEED UP을 위한 기능
1. Auto Clustering vs Re Clustering
Auto Clustering은 테이블을 생성할 때 클러스터링 키로 설정된 컬럼을 기준으로 데이터를 검색하여 쿼리 성능을 향상시키는 기술이다. 일반적으로 테이블에 저장된 데이터는 클러스터링 키로 설정된 컬럼을 기준으로 데이터를 분할한 뒤 마이크로 파티션 단위로 저장된다. Snowflake는 클러스터링 정보를 활용해서 쿼리를 수행할 때 마이크로 파티션의 불필요한 스캔을 방지하여 쿼리의 성능을 향상시킨다. Auto Clustering을 사용하면 클러스터링 된 테이블의 상태를 지속적으로 모니터링하고 있다가 데이터의 변경이 일어날 때 다시 Clustering이 필요하다고 판단되면 자동(Auto)으로 Clustering하게 된다. 만약 클러스터링 키를 명시적으로 지정하지 않았다면 Snowflake에서 테이블의 첫번째 컬럼이 기본 클러스터링 키로 설정하게 된다.
-- COL1, COL2 컬럼을 클러스터 키로 지정
CREATE TABLE my_table (
col1 STRING,
COL2 INTERGER,
COL3 DATE
)
CLUSTER BY (COL1, COL2);클러스터링 된 테이블이 정의된 후 항상 클러스터링이 일어나게 되는 것은 아니다. Snowflake는 데이터의 변경이 발생하고 클러스터링이 필요하다고 판단이 될 때 다시 클러스터링 하게 된다. 이러한 작업은 ALTER TABLE ... SUSPEND / RESUME RECLUSTER를 사용하여 언제든지 클러스터링 된 테이블에 대한 Auto Clustering을 일시 중지하고 다시 시작할 수 있다. 일시 중지되면 테이블은 클러스터링 상태와 상관 없이 자동으로 Re Clustering 되지 않으므로 관련 크레딧 비용이 발생하지 않는다.
이러한 방식의 Auto Clustering에도 한계가 있다. 새로운 데이터의 유입과 다양하고 복잡한 쿼리를 처리하는 데 현재의 클러스터 키로 다시 클러스터링을 해도 더 나은 쿼리 성능 개선을 이뤄내지 못하다고 판단이 되면 사용자가 임의로 다른 컬럼을 클러스터 키로 지정해 클러스터링 할 수 있다. 이러한 방식을 Re Clustering이라고 한다.
Re Clustering은 클러스터링 된 테이블에서 쿼리가 충분히 빠르지 않고 자주 필터링 되는 조건 컬럼이 있는 테이블에 대하여 최적의 클러스터링을 유지하기 위해 테이블을 주기적/정기적으로 Re Clustering 하는 작업을 말한다. 테이블의 데이터가 Re Clustering 될 때마다 테이블의 Clustering Key를 기반으로 행이 물리적으로 그룹화되어 새로운 Micro-Partition을 생성하게 된다. 두 개 이상의 컬럼에 대한 Clustering Key를 지정할 수 있으며 이러한 Clustering Key에 따라 그룹화하여 저장하게 된다.
아래의 예를 보며 이해해보자. 테이블을 Re Clustering 해서 Micro-Partition 스캔을 줄여 쿼리 성능을 향상시키는 예시이다.
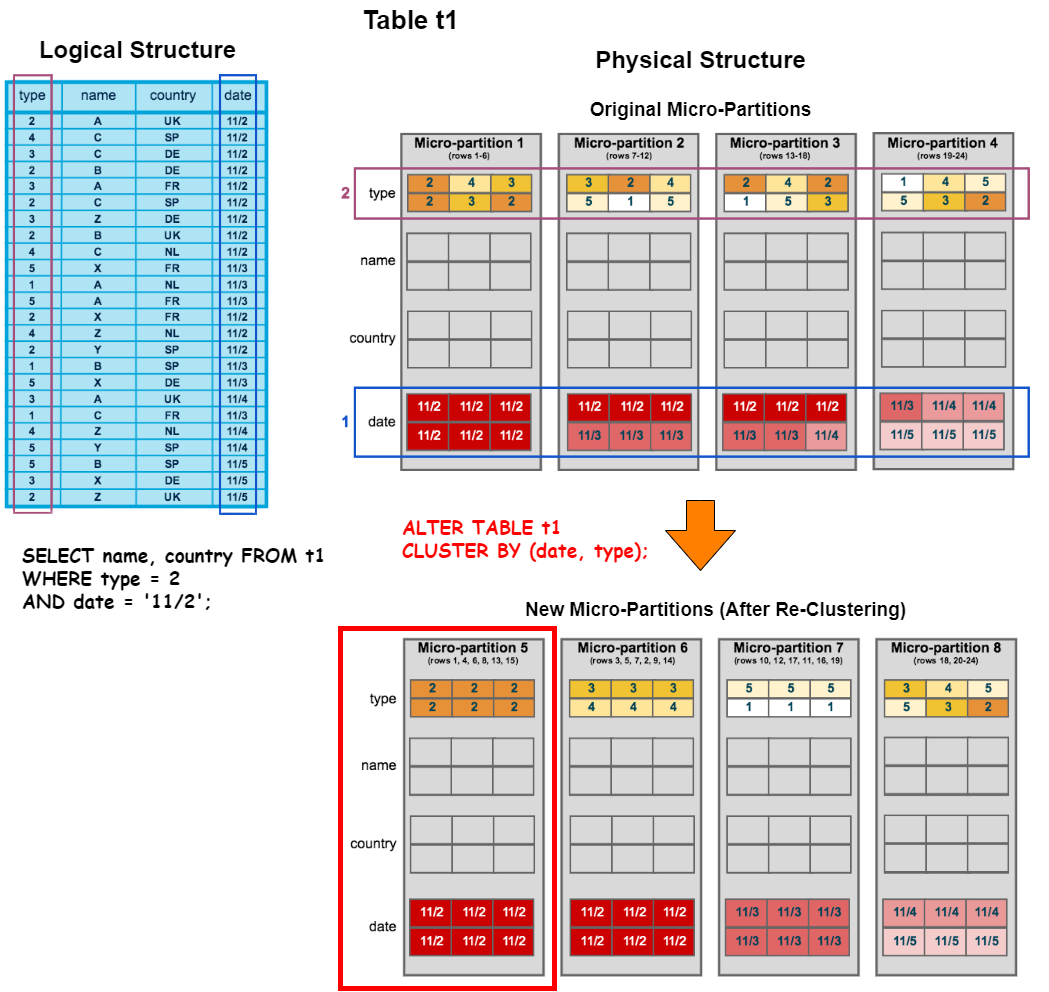
데이터가 들어온 순서에 따라 Micro-Partition 1~4에 걸쳐 클러스터링 된다. 기존 쿼리는 Micro-Partition 1, 2, 3을 스캔해야 했다. 이후 date와 type 컬으로 Re Clustering Key를 정의하고 Re Clustering을 수행하면 새로운 Micro-Partition (5~8)이 생성된다. Re Clustering 이후 앞서 수행한 동일한 쿼리는 이전과 다르게 Micro-Partition 5만 스캔하게 되어 더 빠른 쿼리 결과를 가져올 수 있게 된다.
| AUTO CLUSTERING | RE CLUSTERING |
| DML 작업이 빈번하게 일어나 현재 파티셔닝 구조가 비효율적인 경우 | DML 작업이 빈번하게 일어나 현재 파티셔닝 구조가 비효율적인 경우 |
| Micro-Partition을 진단하여 재구성 | 직접 Clustering Key를 지정할 수 있음 |
| 백그라운드에서 SERVERLESS로 자동 Re Clustering | Multi Column에 대한 Cluster Key 지정 가능 |
| Re Clustering 되는 동안 DML 수행 가능 | TB 단위가 넘는 테이블에 대해서 권고 |
2. SEARCH OPTIMIZATION
Search Optimization(검색 최적화)은 RDBMS의 인덱싱 기능과 비슷하다. 쉽게 말해서 쿼리 조회 조건 별로 인덱스를 생성해서 쿼리 성능을 높이는 기술이다. 최적의 쿼리 응답 속도를 보장하기 위해 SEARCH OPTIMIZATION 키워드를 통해 특정 쿼리 조건에 대한 컬럼을 지정하여 쿼리 성능을 향상 시키는 것을 목표로 한다.
Search Optimization은 다음과 같은 사용자를 대상으로 특정 유형의 쿼리 성능을 크게 향상 시키는 것을 목표로 한다.
- 고도로 선택적인 조건절을 사용하여 빠른 성능의 응답이 필요한 비즈니스 사용자
- 방대한 양의 데이터 내에서 특정 서브 집합을 찾는 분석가
- 광범위한 검색 조건(equality, IN, ARRAY_CONTAINS, ARRAYS_OVERLAP 등) 세트를 대상으로 검색하는 데이터 어플리케이션
Search Optimization 서비스는 해당 테이블과 컬럼에 대한 Search Access Path(검색 액세스 경로)를 생성하여 쿼리 속도를 보장하는 방식이다. 이는 백그라운드에서 SERVERLESS로 수행되며 검색 액세스 경로 생성 및 유지 관리를 담당하게 된다.
Search Optimization을 사용하면 해당 쿼리에 사용되는 테이블과 컬럼에 대한 검색 최적화를 구성할 수 있다. Search Optimization 서비스는 해당 테이블과 열에 대한 Search Access Path(검색 액세스 경로)를 생성하게 되고 이는 백그라운드에서 SERVERLESS 환경으로 수행된다. 백그라운드에서 실행되는 유지 관리 서비스는 Search Access Path(검색 액세스 경로) 생성 및 유지 관리를 담당한다. 아래 예시를 살펴보자.
ALTER TABLE t1 ADD SEARCH OPTIMIZATION ON EQUALITY(col1), RANGE(col2), ORDER(col3);위 쿼리는 t1 테이블에서 col1 열에서의 동등 조건 검색, col2 열에서의 범위 검색, col3 열에서의 정렬 검색에 대해 Search Optimization을 적용한다.
Search Optimization이 적용된 테이블에서 index를 사용할 수 있는 조회 쿼리문 예시이다.
--col1 열에서 동등 조건 검색
SELECT * FROM t1 WHERE col1 = 'value';
--col2 열에서 범위 조건 검색
SELECT * FROM t1 WHERE col2 > 10 AND col2 < 20;
--col3 열에서 정렬 조건 검색
SELECT * FROM t1 ORDER BY col3;위 쿼리들은 각각 col1, col2, col3 열에서의 검색에 대해 Search Optimization이 적용되어 있으므로 index를 사용하여 빠른 검색을 수행할 수 있다.
다음은 같은 동등 조건 검색일지라도 사용 방식에 따라 index를 다르게 설정할 수도 있는 예시이다.
컬럼 col1 ,col2, col3 에 대한 Equality 검색을 사용하여 검색을 최적화
ALTER TABLE t1 ADD SEARCH OPTIMIZATION ON EQUALITY(col1, col2, col3);
--조건절에 col1, col2만 있으면 최적의 성능 나오지 않음위의 쿼리는 조건문에 col1, col2, col3 컬럼을 모두 사용해야 최적의 성능을 뽑아낼 수 있다.
ON 절에서 동일한 검색 방법을 두 번 이상 지정할 수도 있다.
ALTER TABLE t1 ADD SEARCH OPTIMIZATION ON EQUALITY(col1), EQUALITY(col2, col3);
--조건절에 col1만 있어도 되지만 col2만 있으면 최적의 성능 나오지 않음위의 쿼리는 조건문에 col2 컬럼만 사용하게 된다면 최적의 성능이 나오지 않는다. 따라서 쿼리 성능을 향상 시키기 위한 적절한 Search Optimization 설정이 중요하다.
SEARCH OPTIMIZATION 서비스 비용 관리
SEARCH OPTIMIZATION 서비스는 스토리지 및 컴퓨팅 리소스 비용에 영향을 미친다.
- 스토리지 리소스 : SEARCH OPTIMIZATION 서비스는 검색 최적화가 활성화된 각 테이블에 대한 공간이 필요한 검색 액세스 경로(Search Access Path)의 데이터 구조를 생성한다. 검색 액세스 경로의 스토리지 비용은 여러 요인에 따라 달라진다. 예를 들면 모든 컬럼이 검색 액세스 경로를 사용하는 데이터 타입을 가지고 있고 각 컬럼의 모든 데이터 값이 고유한 경우 필요한 스토리지는 원본 테이블의 크기만큼 커질 수 있다.
- 컴퓨팅 리소스 : 기본적으로 테이블에 Search Optimization을 추가하면 리소스가 소모되고 이를 유지하기 위한 리소스도 뒤따른다. 또한 테이블에 대한 데이터 변경 사항이 많을 때 더 많은 리소스가 소모된다.
※ Auto Clustering은 검색 최적화를 통해 테이블의 쿼리 대기 시간을 개선하는 동시에 검색 최적화의 유지 관리 비용을 더욱 증가 시킬 수 있다. 테이블의 변동률이 높은 경우 Auto Clustering을 활성화하고 테이블에 대한 검색 최적화를 구성하는 테이블이 검색 최적화용으로 구성된 경우보다 유지 관리 비용이 높아질 수 있다.
Snowflake는 사용한 실제 리소스에 대해서만 계정에 요금을 청구하여 효율적인 크레딧 사용을 보장한다. 하지만 무분별한 사용으로 과도한 요금(1초 단위로 계산)이 청구될 수 있으므로 처음의 몇 개의 테이블에만 검색 최적화를 추가하는 등 검색 최적화를 사용하는데 발생하는 이점과 요금을 면밀히 모니터링 할 것을 권장한다.
비용 추정
SYSTEM$ESTIMATE_SEARCH_OPTIMIZATION_COSTS 함수를 통해 비용을 예측할 수 있다. 이를 통해 테이블에 검색 최적화를 추가하고 검색 최적화를 위해 특정 컬럼을 구성하는 비용을 추정한다. 아래는 테이블에 대한 검색 최적화 비용을 예측하는 쿼리이다.
-- 특정 테이블에 대한 검색 최적화 비용 예측
SYSTEM$ESTIMATE_SEARCH_OPTIMIZATION_COSTS('<table_name>')
SELECT SYSTEM$ESTIMATE_SEARCH_OPTIMIZATION_COSTS('TABLE_WITH_SEARCH_OPT');
+---------------------------------------------------------------------------+
| SYSTEM$ESTIMATE_SEARCH_OPTIMIZATION_COSTS('TABLE_WITH_SEARCH_OPT') |
|---------------------------------------------------------------------------|
| { |
| "tableName" : "TABLE_WITH_SEARCH_OPT", |
| "searchOptimizationEnabled" : true, |
| "costPositions" : [ { |
| "name" : "BuildCosts", |
| "computationMethod" : "NotAvailable", |
| "comment" : "Search optimization is already enabled." |
| }, { |
| "name" : "StorageCosts", |
| "costs" : { |
| "value" : 0.052048, |
| "unit" : "TB" |
| }, |
| "computationMethod" : "Measured" |
| }, { |
| "name" : "Benefit", |
| "computationMethod" : "NotAvailable", |
| "comment" : "Currently not supported." |
| }, { |
| "name" : "MaintenanceCosts", |
| "costs" : { |
| "value" : 30.248, |
| "unit" : "Credits", |
| "perTimeUnit" : "MONTH" |
| }, |
| "computationMethod" : "EstimatedUpperBound", |
| "comment" : "Estimated from historic change rate over last ~11 days." |
| } ] |
| } |
+---------------------------------------------------------------------------+
각 속성에 대해 알아보자.
| Property | Description |
| tableName | 테이블 명 |
| searchOptimizationEnabled | 테이블에 대한 검색 최적화 설정 여부 |
| costPositions | 테이블에 검색 최적화를 추가하는 예상 비용 설명 |
| costPositions의 name 객체 | Description |
| BuildCosts | 테이블에 대한 검색 액세스 경로를 빌드하는 예상 비용 |
| StorageCosts | 테이블의 검색 액세스 경로에 필요한 스토리지 공간의 예상 크기(TB) |
| Benefit | 현재 비용 정보가 포함되어 있지 않음 |
| MaintenanceCosts | 테이블에 대한 검색 액세스 경로 유지보수의 예상 비용 |
일반적으로 비용은 다음에 비례한다.
- 기능이 활성화된 테이블 수와 해당 테이블의 고유 값 수
- 테이블에서 변경되는 데이터의 양
비용 절감
검색 최적화를 활성화할 테이블을 신중하게 선택하여 비용을 제어할 수 있다. 비용을 줄이기 위한 다음과 같은 작업을 권장한다.
- DML 작업 일괄 처리 권장
- DELETE : 테이블이 가장 최근 기간의 데이터를 저장하는 경우 오래된 데이터를 삭제하여 테이블을 다듬을 때 검색 최적화 서비스에서 업데이트를 고려해야 한다. 즉 DELETE 빈도를 줄임으로써 비용을 절감할 수 있다.
- INSERT, UPDATE, MERGE : 테이블에서 이러한 유형의 DML 작업을 일괄 처리하면 검색 최적화 서비스의 유지 관리 비용을 절감할 수 있다.
- 전체 테이블을 RE CLUSTERING 하는 경우 RE CLUSTERING 하기 전에 SEARCH OPTIMIZATION 속성을 삭제한 다음 RE CLUSTERING 한 후 테이블에 SEARCH OPTIMIZATION 속성을 다시 추가한다.
3. Materialized View
Materialized View는 반복적인 쿼리 연산에 시간과 비용을 낭비하지 않도록 자주 사용하는 예측 및 집계를 미리 저장하는 계산된 데이터 세트이다. 데이터가 미리 계산되어 저장되기 때문에 Materialized View에 쿼리를 실행하는 것이 기본 테이블에 대해 쿼리를 실행하는 것보다 빠르다. Materialized View는 일반적으로 반복되는 쿼리 패턴으로 구성된 워크로드에 대한 쿼리 성능을 개선하도록 설계되었다. 비용이 많이 드는 집계, 프로젝션 및 선택 작업, 특히 자주 실행되는 대규모 데이터 세트에서 실행되는 작업 속도를 높일 수 있다. 또한 앞서 Storage Layer에서 설명했던 것처럼 Snowflake 외부에 있는 External Table(외부 테이블)에 대한 쿼리 조회는 그 속도가 느리다는 단점이 있었다. 그러나 이는 외부 테이블을 기반으로 하는 Materialized View로 쿼리 성능을 향상 시킬 수 있다. 아래 그림은 외부 테이블을 기반으로 Materialized View를 생성하는 예시이다.

Materialized View 를 생성하는 구문은 아래와 같다.
CREATE MATERIALIZED VIEW my_mv
COMMENT='Test View'
AS
SELECT col1, col2 FROM my_table;Materialized View의 장점
- 동일한 subquery 결과를 반복적으로 사용하는 쿼리의 성능을 향상 시킬 수 있다.
- Materialized View를 통해 액세스 된 데이터는 기본 테이블에서 수행된 DML의 양에 상관 없이 항상 최신 상태를 유지한다. 만약 MV가 최신 상태가 되기 전에 쿼리가 실행되면 Snowflake는 MV를 업데이트하거나 MV의 최신 부분을 사용하고 기본 테이블에서 필요한 최신 데이터를 검색한다.
- Materialized View를 생성한 후 백그라운드 프로세스는 Materialized View의 데이터를 자동으로 유지 관리한다.

테이블, Regular View 및 캐시된 결과와의 비교
Materialized View는 테이블과 유사하기도 하고 향후 재사용을 위해 쿼리 결과를 저장한다는 점에서 캐시된 결과와도 유사한 특징을 가지고 있다. Snowflake는 쿼리가 실행된 후 일정 시간 동안 쿼리 결과를 캐시한다. 따라서 동일한 쿼리가 재실행되면 Snowflake는 쿼리를 다시 실행하지 않고 동일한 결과를 반환할 수 있다. 이에 대한 내용은 앞서 Compute Layer에서 다루었다.
이처럼 Materialized View와 캐시된 쿼리 결과 모두 쿼리 성능 이점을 제공한다. Materialized View는 캐시된 결과보다 유연하지만 느리고 '캐시' 때문에 테이블보단 빠르다. Regular View는 데이터를 캐시하지 않으므로 캐시를 통해 성능을 향상 시킬 수는 없다. 하지만 경우에 따라 Regular View는 Snowflake가 보다 효율적인 쿼리 계획을 생성하는 데 도움이 된다.
아래의 표는 테이블, Regular View, 캐시된 쿼리 결과 및 Materialized View 간의 유사점과 차이점을 보여준다.

Materialized View에 대한 기본 테이블 변경의 영향
Snowflake에서 기본 테이블에 대한 변경 사항은 해당 테이블을 기반으로 하는 Materialized View에 적용되지 않는다. 만약 기본 테이블에 컬럼이 추가되어도 Materialized View엔 업데이트 되지 않는다. 따라서 기본 테이블이 변경되어 기존 컬럼이 변경되거나 삭제되면 Materialized View도 다시 새롭게 생성해야 한다. 또한 기본 테이블이 삭제되면 Materialized View가 일시 중지되지만 자동으로 삭제되지는 않는다. 이러한 이유로 직접 Materialized View를 삭제해야 한다.
4. Query Acceleration
Query Acceleration 서비스는 작은 Warehouse 사이즈를 사용하면서도 특정 쿼리 처리에 대한 병렬도를 높여서 쿼리 처리 시간을 단축 시키는 기능이다. 예를 들면 XS 사이즈의 Warehouse(서버 1대)가 있다고 가정 했을 때 특정 쿼리를 수행할 때만 n대로 확장(Scale Out)이 가능하다.
- Warehouse를 수동으로 Size Up 하지 않고 쿼리 런타임 축소
- Warehouse에 미치는 "oversized" 쿼리의 영향 감소
- 오버사이징 Warehouse에 대한 비용 문제 해결
- 가장 큰 Warehouse 크기 이상으로 성능 확장

Query Acceleration 을 설정하는 방법은 간단하다. Warehouse를 생성할 때 enable_query_acceleration 설정 여부와 query_acceleration_max_scale_factor 키워드를 설정해주면 된다. 이는 Warehouse별로 활성화가 가능하다.
CREATE warehouse my_wh WITH
enable_query_acceleration = TRUE --Query Acceleration 활성화
query_acceleration_max_scale_factor = 3; --Default 8

병렬화로 성능 향상이 가능한 쿼리에 대해 Warehouse 엔진을 동적으로 자동으로 확장시킬 수 있고 최대 max_scale_factor 만큼 Scale Out을 수행하기 때문에 사용자가 직접 쿼리별로 Warehouse에 대한 크기를 조정할 필요 없이 SCALE FACTOR(0~100)만 지정해주면 된다.
5. Snowpipe
S3와 같은 외부 클라우드 저장소(Stage)에서 Snowflake로 데이터를 가져오는 방법은 Bulk Load 방식과 Continuous 방식이 있다. 그 중 Continuous 방식으로 가져올 때 사용하는 Snowpipe에 대해 알아보자. Stage에서 파일(데이터)를 감지하는 방식은 아래와 같이 두가지로 나뉘어진다.
- 클라우드 메시징을 통한 Snowpipe 자동화
- Snowpipe REST End Point 호출
클라우드 메시징을 통한 Snowpipe 자동화
S3는 데이터의 지속적 처리를 위해 이벤트 알림 옵션을 사용하여 새로운 데이터가 들어오면 SQS에 Notification을 주는 기능이 있다. Snowpipe는 그 Notification을 보고 있다가 새로 들어온 데이터만 Snowflake로 데이터를 가져오게 된다. 즉, 일정에 따라 COPY 문을 수동으로 실행하는 방식이 아닌 사용자가 몇 분 내에 사용할 수 있도록 마이크로 배치로 데이터를 Load 할 수 있게 된다. Snowpipe는 지정된 파이프 오브젝트에 정의된 매개 변수를 기반으로 Continuous Serverless 방식으로 대상 테이블에 Load 되는 큐에 파일을 복사해서 파일(데이터)를 가져온다.

Snowpipe REST End Point 호출
주로 어플리케이션에서 작동하는 방식으로 파이프 오브젝트의 이름과 파일(데이터)의 이름 목록을 사용하여 REST End Point를 호출한다. 파이프 오브젝트가 참조하는 Stage(S3)에서 목록과 일치하는 새 데이터 파일이 발견되면 이를 Load 할 수 있도록 큐에 추가한다. 이때도 마찬가지로 파이프에 정의된 매개 변수를 기반으로 큐에서 Snowflake 테이블로 데이터를 Load 한다.

위의 과정을 간략하게 설명하자면 데이터 파일은 내부(Snowflake) 또는 외부(Amazon S3, 현재*2023년 3월 기준 한국은 Amazon만 지원) Stage에 복사 된다. 클라이언트는 수집할 파일 목록과 정의된 파이프를 사용하여 InsertFiles End Point를 호출하게 된다. End Point는 이러한 파일을 수집 큐로 이동 시키고 Snowflake의 Virtual Warehouse는 지정된 파이프에 정의된 매개 변수를 기반으로 큐에서 대기 중인 파일의 데이터를 대상 테이블로 Load 하게 된다.
데이터 파일 Load 순서
각 파이프 오브젝트에 대해 Snowflake는 Load 대기 중인 데이터 파일의 순서를 지정하는 단일 큐를 설정한다. Stage에서 새 데이터 파일이 발견되면 Snowflake는 해당 파일을 큐에 추가하게 된다. 그러나 여러 프로세스가 큐에서 파일을 가져오므로 일반적으로 Snowpipe는 더 오래된 파일을 먼저 Load하지만 Staging 된 순서대로 파일이 Load 된다는 보장은 없다.
데이터 중복
Snowpipe는 각 파이프 오브젝트와 연결된 파일 Load 메타데이터를 사용하여 테이블에서 동일한 파일(중복 데이터)이 다시 Load 되는 것을 방지한다. 이 메타데이터를 통해 Load 된 각 파일의 경로 및 파일 명을 저장하고 나중에 수정된 동일한 이름의 파일이 Load 되는 것을 방지한다.