Snowflake Cortex AI 함수는 주로 비정형 데이터(텍스트, 이미지 등) 분석에 LLM을 활용한다. 공식 문서에 따르면 아래와 같은 것들을 지원한다고 한다.
- 엔터티 추출을 위한 메타데이터 보강 및 유효성 검사 간소화
- 고객 티켓 전반에서 인사이트 집계하기
- 자연어로 내용 필터링 및 분류하기
- 서비스 개선을 위한 감성 및 양상 기반 분석
- 다국어 내용 변환 및 로컬라이제이션
- 분석 및 RAG 파이프라인을 위한 문서 구문 분석하기
이렇게만 봐서는 어떤 것들이 가능한지 확 와닿진 않기 때문에 실제로 비정형 데이터를 토대로 여러가지 함수를 직접 실행해보며 테스트해보자.
우선 기본적인 오브젝트를 생성한다.
-- OBJECT 생성
CREATE DATABASE HD_DEMO;
CREATE SCHEMA HD_DEV;
-- STAGE 생성
CREATE STAGE DEMO_STAGE
DIRECTORY = ( ENABLE = true )
ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );
-- 리전 간 추론 허용
ALTER ACCOUNT SET CORTEX_ENABLED_CROSS_REGION = 'ANY_REGION';
-- STAGE 내 데이터 확인
LS @DEMO_STAGE;
테스트에 사용될 데이터는 아래와 같은 png 파일과 음성 데이터를 준비했다.

[1-1] 전처리 > Voice to text
SELECT 'news.mp3' AS FILE
, AI_TRANSCRIBE(
TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'news.mp3')
) AS TRANSCRIBED_RESULT
UNION ALL
SELECT 'news2.mp3' AS FILE
, AI_TRANSCRIBE(
TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'news2.mp3')
) AS TRANSCRIBED_RESULT;
[1-2] 전처리 > Description from image
SELECT AI_COMPLETE('claude-4-sonnet',
'이미지에 대해서 2줄로 설명해줘.',
TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'sad.png')
) AS IMG_DESCRIPTION
UNION ALL
SELECT AI_COMPLETE('openai-gpt-4.1',
'이미지에 대해서 2줄로 설명해줘.',
TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'sad.png')
) AS IMG_DESCRIPTION
UNION ALL
SELECT AI_COMPLETE('openai-gpt-4.1',
'이미지에 대해서 2줄로 설명해줘.',
TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'beoruk.png')
) AS IMG_DESCRIPTION
;
위와 같이 정확하게 이미지에 대한 설명을 하고 있는 것을 확인할 수 있고, 모델별로도 동일한 이미지에 대해 설명의 차이가 있는 것을 확인할 수 있다.
[2-1] 추출 > 감정 분류 (Classification from image)
SELECT AI_CLASSIFY(
PROMPT('해당 이미지의 {0} 상태는?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'sad.png'))
, ['Normal', 'Damaged', 'Happy', 'Nervous', 'Angry', 'Sad']
) AS RESULT
UNION ALL
SELECT AI_CLASSIFY(
PROMPT('해당 이미지의 {0} 상태는?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'angry.png'))
, ['Normal', 'Damaged', 'Happy', 'Nervous', 'Angry', 'Sad']
) AS RESULT
UNION ALL
SELECT AI_CLASSIFY(
PROMPT('해당 이미지의 {0} 상태는?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'beoruk.png'))
, ['Normal', 'Damaged', 'Happy', 'Nervous', 'Angry', 'Sad']
) AS RESULT
;
[2-2] 추출 > 날씨 분류 (Classification from image)
SELECT AI_CLASSIFY(
PROMPT('해당 이미지의 {0} 날씨는?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'sunny.png'))
, ['Normal', 'Cloudy', 'Sunny', 'Thunderstorm', 'Snowy', 'Foggy', 'Rainy']
) AS RESULT
UNION ALL
SELECT AI_CLASSIFY(
PROMPT('해당 이미지의 {0} 날씨는?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'thunder.png'))
, ['Normal', 'Cloudy', 'Sunny', 'Thunderstorm', 'Snowy', 'Foggy', 'Rainy']
) AS RESULT
UNION ALL
SELECT AI_CLASSIFY(
PROMPT('해당 이미지의 {0} 날씨는?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'cloudy.png'))
, ['Normal', 'Cloudy', 'Sunny', 'Thunderstorm', 'Snowy', 'Foggy', 'Rainy']
) AS RESULT
;
AI_COMPLETE 함수를 사용해도 된다.
SELECT AI_COMPLETE(
'openai-gpt-4.1'
, '설명은 하지말고 날씨를 확인해보고 알려줘.'
, TO_FILE('@"SSG_DEMO"."SSG_DEV"."DEMO_STAGE"', 'cloudy.png')) AS IMG_DESCRIPTION
;
[2-3] 추출 > 과일 분류 (Classification from image)
SELECT AI_CLASSIFY(
PROMPT('해당 이미지는 {0} 어떤 과일인가?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'apple.png'))
, ['Apple', 'Banana', 'Mango', 'Grape', 'Applemango']
) AS RESULT
UNION ALL
SELECT AI_CLASSIFY(
PROMPT('해당 이미지는 {0} 어떤 과일인가?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'mango.png'))
, ['Apple', 'Banana', 'Mango', 'Grape', 'Applemango']
) AS RESULT
UNION ALL
SELECT AI_CLASSIFY(
PROMPT('해당 이미지는 {0} 어떤 과일인가?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'applemango.png'))
, ['Apple', 'Banana', 'Mango', 'Grape', 'Applemango']
) AS RESULT
UNION ALL
SELECT AI_CLASSIFY(
PROMPT('해당 이미지는 {0} 어떤 과일인가?'
, TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'grape.png'))
, ['Apple', 'Banana', 'Mango', 'Grape', 'Applemango']
) AS RESULT
;
[2-4] 추출 > 뉴스 1에 대한 분류(내용 확인)
WITH TRANS_RSLT AS
(
SELECT AI_TRANSCRIBE(
TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'news.mp3')
) AS TRANS_TXT
)
SELECT AI_CLASSIFY('아래 내용의 주된 세대를 분류해주세요 :' || TRANS_TXT:text::STRING
, ['2030', '4050', '6070']
):labels AS CLASSIFICATION
FROM TRANS_RSLT
;
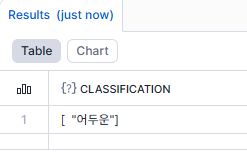
[2-5] 추출 > 뉴스 1에 대한 분류(분위기 확인)
WITH TRANS_RSLT AS
(
SELECT AI_TRANSCRIBE(
TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'news.mp3')
) AS TRANS_TXT
)
SELECT AI_CLASSIFY('아래 내용의 분위기를 분류해주세요 :' || TRANS_TXT:text::STRING
, ['희망적인', '절망적인', '어두운', '용기있는', '미래지향적인']
):labels AS CLASSIFICATION
FROM TRANS_RSLT
;
[2-6] 추출 > 뉴스 2에 대한 분류(내용 확인)
WITH TRANS_RSLT AS
(
SELECT AI_TRANSCRIBE(
TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'news2.mp3')
) AS TRANS_TXT
)
SELECT AI_CLASSIFY('아래 내용의 피해를 분류해주세요 :' || TRANS_TXT:text::STRING
, ['홍수', '가뭄', '폭설', '산사태']
):labels AS classification
FROM TRANS_RSLT
;
[2-6] 추출 > Extract data from doc
SELECT AI_EXTRACT(
FILE => TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'voucher.pdf'),
responseFormat => [['Name', 'What is the Guest Name?']
, ['City', 'Where is the Resort?']
, ['Resort Name', 'What is the Resort Name?']
, ['Check-in', 'What is check in date?']]
)
;
[2-7] 활용
-- 1. 먼저 음성을 텍스트로 변환 (Transcribe)
WITH news_data AS (
SELECT
RELATIVE_PATH as file_name,
-- 음성 -> 텍스트 변환
AI_TRANSCRIBE(
TO_FILE('@DEMO_STAGE', RELATIVE_PATH)
):text::STRING as raw_text
FROM DIRECTORY(@DEMO_STAGE)
WHERE RELATIVE_PATH IN ('news.mp3', 'news2.mp3')
)
-- 2. 변환된 텍스트를 다양하게 가공 (Preprocessing)
SELECT
file_name,
-- [Case 1: 글로벌 대응] 해외 지사 공유를 위한 영문 번역
SNOWFLAKE.CORTEX.TRANSLATE(raw_text, 'ko', 'en') AS translated_english,
-- [Case 2: 데이터 엔지니어링] 핵심 정보(날짜, 수치, 장소)만 JSON 추출
-- (비정형 뉴스 -> 정형 데이터로 변환)
AI_COMPLETE(
'claude-4-sonnet',
'다음 뉴스 텍스트에서 중요한 "날짜(Date)", "장소(Location)", "핵심수치(Key_Numbers)"를 추출해서 JSON 포맷으로만 답변해줘: ' || raw_text
) AS extracted_json,
-- [Case 3: 서비스 적용] 뉴스 내용 기반 자동 공지사항 초안 작성
AI_COMPLETE(
'claude-4-sonnet',
'너는 쇼핑몰 운영자야. 이 뉴스를 바탕으로 고객에게 보낼 "서비스 영향 안내 공지문"을 정중하게 작성해줘. (예: 배송지연, 소비 트렌드 변화 등)' || raw_text
) AS notice_draft
FROM news_data;
[3-1] 변환
CREATE OR REPLACE TABLE TRANS_RSLT
AS
SELECT AI_TRANSCRIBE(
TO_FILE('@"HD_DEMO"."HD_DEV"."DEMO_STAGE"', 'news2.mp3')
) AS TRANS_TXT
;
SELECT
TRANS_TXT:text::STRING AS TXT,
SNOWFLAKE.CORTEX.TRANSLATE(TXT, 'KO','EN' ) AS TXT_EN,
AI_TRANSLATE(TXT, 'KO','EN' ) AS TXT_EN_AI,
SNOWFLAKE.CORTEX.SUMMARIZE(TXT_EN) AS SUMMARY_TXT,
SNOWFLAKE.CORTEX.TRANSLATE(SUMMARY_TXT, 'EN', 'KO') AS SUMMARY_TXT_KO,
AI_SENTIMENT(SUMMARY_TXT),
AI_SENTIMENT(TXT_EN, ['Communication Skills','Standard Greeting']),
FROM TRANS_RSLT;
[3-2] 활용
고객의 컴플레인 내용을 담은 테이블을 생성해놓고 그에 대한 응답 메뉴얼을 가진 테이블을 생성한다. 이후, 특정 컴플레인에 대한 적절한 응답을 할 수 있는지 확인해본다.
-- ###############################
-- 고객 COMPLAIN 테이블 생성
-- ###############################
SELECT * FROM HD_DEV.CUSTOMER_TEXT;
-- ###############################
-- 응답 메뉴얼 테이블 생성
-- ###############################
SELECT * FROM HD_DEV.RESPONSE_MANUAL;

SELECT A.COMPLAIN
, B.RESPONSE
FROM CUSTOMER_TEXT A
, RESPONSE_MANUAL B
WHERE AI_FILTER(PROMPT('"{1}"은 "{0}"의 답변으로 적합합니다.', COMPLAIN, RESPONSE)) = TRUE
ORDER BY A.COMPLAIN
;
다음은 AI_COMPLETE 함수를 활용해서 적절한 프롬프트를 입력하여 각 컴플레인에 대한 답변이 어느정도 적절한지 점수로 출력해보자.
WITH T1 AS (
SELECT A.COMPLAIN
, B.RESPONSE
FROM HD_DEV.CUSTOMER_TEXT A
CROSS JOIN HD_DEV.RESPONSE_MANUAL B
)
SELECT COMPLAIN
, RESPONSE
, AI_COMPLETE(
'openai-gpt-4.1'
, PROMPT('"{0}"과 "{1}"을 비교해서
답변이 얼마나 문의내용을 충족하는지 평가해줘.
출력은 0과 100점 사이의 점수만 출력해줘.
다른 답변은 출력하지마.', COMPLAIN, RESPONSE)) AS SCORING
FROM T1
ORDER BY COMPLAIN, SCORING DESC
;
[4] 개인 식별 정보 제거
--기본 정보 (이름, 전화번호, 이메일)
SELECT AI_REDACT(
input => '안녕하세요, 제 이름은 김철수입니다. 연락처는 010-1234-5678이고, 이메일 주소는 chulsu.kim@example.com입니다.'
)
UNION ALL
-- 고유 식별 정보 (주민등록번호 포함)
SELECT AI_REDACT(
input => '신청자의 주민등록번호는 900101-1234567입니다. 반드시 본인 확인 후 처리 바랍니다.'
)
UNION ALL
-- 주소 및 위치 정보
SELECT AI_REDACT(
input => '배송지는 서울특별시 강남구 테헤란로 123, 101동 202호입니다. 빠른 배송 부탁드립니다.'
)
UNION ALL
-- 금융 정보 (카드 번호)
SELECT AI_REDACT(
input => '이번 달 결제는 신한카드 1234-5678-9012-3456으로 진행되었습니다. 유효기간은 12/28입니다'
)
UNION ALL
-- 비정형 로그 데이터 (혼합)
SELECT AI_REDACT(
input => '[LOG] User: 이영희(leeyh), IP: 192.168.0.1, Phone: 02-555-7777, ReqID: ABC-12345 접근 승인됨.'
);
[5] 유사도 평가
-- 문장1, 문장2 사이의 유사도 점수를 계산
SELECT
t.case_type AS "테스트 유형",
t.text1 AS "문장 1",
t.text2 AS "문장 2",
AI_SIMILARITY(t.text1, t.text2) AS "유사도 점수"
FROM (
-- 1. [높음] 문장 구조는 다르지만 의미가 거의 같은 경우 (Paraphrasing)
SELECT
'동의어/구조 변경' AS case_type,
'이 쿼리는 실행 속도가 너무 느립니다.' AS text1,
'데이터 조회 성능에 문제가 있어 보입니다.' AS text2
UNION ALL
-- 2. [높음] 구체적인 상황 묘사 (배송 관련)
SELECT
'상황 묘사',
'배송이 생각보다 빨리 도착했어요.' AS text1,
'주문한 다음 날 바로 물건을 받았습니다.' AS text2
UNION ALL
-- 3. [중간~높음] 긍정/부정 표현 (감성 분석)
SELECT
'감정 표현',
'영화가 정말 재미있고 감동적이었어.' AS text1,
'내 인생 최고의 명작을 만난 기분이야.' AS text2
UNION ALL
-- 4. [낮음] 키워드는 겹치지만 문맥이 완전히 다른 경우 (동음이의어 테스트)
SELECT
'문맥 차이(함정)',
'사과(Apple)를 한 상자 주문했습니다.' AS text1,
'그 실수에 대해서는 정중히 사과(Apology)드립니다.' AS text2
UNION ALL
-- 5. [낮음] 전혀 관계없는 주제
SELECT
'관계 없음',
'오늘 점심 메뉴는 김치찌개입니다.' AS text1,
'스노우플레이크 주가가 오늘 상승했습니다.' AS text2
) t
ORDER BY "유사도 점수" DESC;
'Snowflake' 카테고리의 다른 글
| [Snowflake] Cortex Search Service 기반 AI 챗봇 질의 (0) | 2025.12.24 |
|---|---|
| [Snowflake] Snowflake Intelligence로 나만의 에이전트를 만들어보자 (0) | 2025.12.11 |
| [Snowflake] Dashboard를 활용하여 모니터링 해보자 (0) | 2025.12.09 |
| [쿼리] Warehouse 사이즈 변경 이력 조회 (0) | 2025.12.04 |
| [분석] Warehouse Info 프로시저 생성 (0) | 2025.12.03 |


