지난 7월, Snowflake는 기존 Kafka용 Snowflake 커넥터 및 ServiceNow와 Google Analytics와 같은 SaaS 애플리케이션용 커넥터의 성공을 바탕으로 MySQL과 PostgreSQL용 커넥터를 새롭게 발표했다. 이번 글에서는 새롭게 출시한 MySQL, PostgreSQL용 커넥터에 대해 알아보고 어떻게 구성되는지와 실제로 커넥터를 활용하여 Snowflake로 데이터를 가져와보도록 하자. 본 글은 Snowflake 공식 튜토리얼을 참고하여 작성하였다.
출처: https://other-docs.snowflake.com/en/connectors/tutorials/dbtutorial

새롭게 출시한 커넥터는 Snowpipe Streaming을 기반으로 구축되어 고객에게 비용 효율적이고 지연 시간이 짧은 파이프라인을 제공할 수 있게 되었다. 또한 OLTP 시스템에서 변경 데이터 캡처(CDC)도 지원하며, 이러한 Native 커넥터는 Snowflake Native 앱 프레임워크로 구축되어 Snowflake Marketplace를 통해 손쉽게 구현할 수 있다. 그럼 이제 Snowflake Native 커넥터가 어떻게 작동하는지 살펴보자.
지원하는 데이터베이스 버전
| 데이터베이스 구분 | MySQL | PostgreSQL |
| 지원 버전 | >= 8.0.0 | >=11 |
| 변경 데이터 확인 방법 | 초기 데이터 적재: SELECT 쿼리 변경 데이터 적재: row based bin log |
초기 데이터 적재: SELECT 쿼리 변경 데이터 적재: logical replication |
| Agent 하드웨어 사양 | 4 cores & 6GB RAM | |
| Agent 설치 및 운영 위치 | 고객사 서버 | |
MySQL과 PostgreSQL 모두 모든 버전을 지원하는 것은 아니다. Snowflake Native 커넥터를 사용하려면 최소 지원하는 버전을 맞춰줘야 하며, 커넥터를 설치하려면 Agent가 같이 설치되어야 하는데 이는 도커 이미지로 배포되며 고객사 인프라에 설치해줘야 한다. 아래와 같이 도커 허브에서도 검색이 가능하다.

아키텍처

아키텍처에서 주목할 부분은 두 가지이다. 바로 Agent와 Native App이다. 앞서 말했듯이 Agent는 도커 이미지로 고객사 서버에 배포되며 Snowflake로 데이터를 Push 하는 데 사용된다. Agent는 Snowpipe Streaming이라는 SDK를 통해 구현이 되고 변경된 데이터를 감지하면 5초 이내로 Snowflake로 적재된다.
Snowflake 이교선 Sales Engineer님에 따르면, Agent 방식으로 이 기능을 제공하는 이유 아래와 같다.
Snowflake에서 고객사 IDC에 접근하는 것은 네트워크나 방화벽 같은 보안 측면으로 해결해야 되는 점들이 많은데, 이는 보안적으로 이슈가 발생할 가능성도 있다. 그렇기 때문에 고객사 인프라에서 Snowflake로 Push 하는 방식이 보안적으로 더 안전화 된 방식이다.
<2024 Snowflake World Tour 서울 中>
Agent
- Docker Hub에서 배포되는 독립 실행형 애플리케이션
- 고객 인프라에 배포되어 소스 데이터베이스 CDC 스트림에서 데이터 변경 사항 추적
- 초기 데이터 및 증분 데이터 전송
Snowflake Native App
- Snowflake 계정 내 객체로 커넥터의 핵심 역할
- 복제 프로세스 관리, Agent 상태 제어, 대상 데이터베이스 객체 생성
커넥터 설치 및 활용
이제 직접 커넥터를 설치해보도록 하자. 테스트는 MySQL과 PostgreSQL 모두 진행했지만 본 글에서는 MySQL 커텍터를 통해 데이터를 가져와 보도록하겠다. 커넥터는 아래와 같이 Marketplace에서 검색 후 설치가 가능하다.
커넥터 설치는 튜토리얼에 나와 있는대로 따라하면 큰 어려움 없이 UI 기반으로 설치가 가능하다.

참고로 Agent를 구성하는데 필요한 파일은 크게 세 가지이다.
- snowflake.json: Snowflake 접속 정보 설정 파일
- datasource.json: 소스 데이터베이스 접속 정보 설정 파일
- JDBC Driver.jar


정상적으로 Agent와 연결이 되었다면 아래와 같은 화면을 볼 수 있다. Agent가 연결이 되면 자동으로 워크시트가 생성되어 편하게 사용할 수 있다.
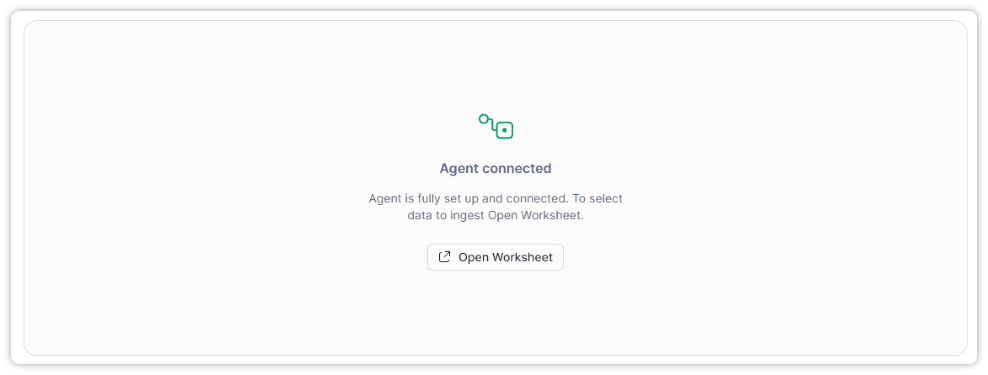
복제할 데이터 소스를 추가하고 테이블까지 지정하게 되면 소스 데이터베이스와 동일한 스키마.테이블이 생성된다.

Agent 및 데이터 동기화와 관련된 모든 작업은 테이블을 통해서 모니터링이 가능하다. 아래 그림을 보면 현재 초기 적재를 진행하고 있는 것을 볼 수 있다.

이후 소스 데이터베이스에서 트랜잭션을 발생시키고 커넥터를 통해서 데이터가 수집되는지 확인해보자.
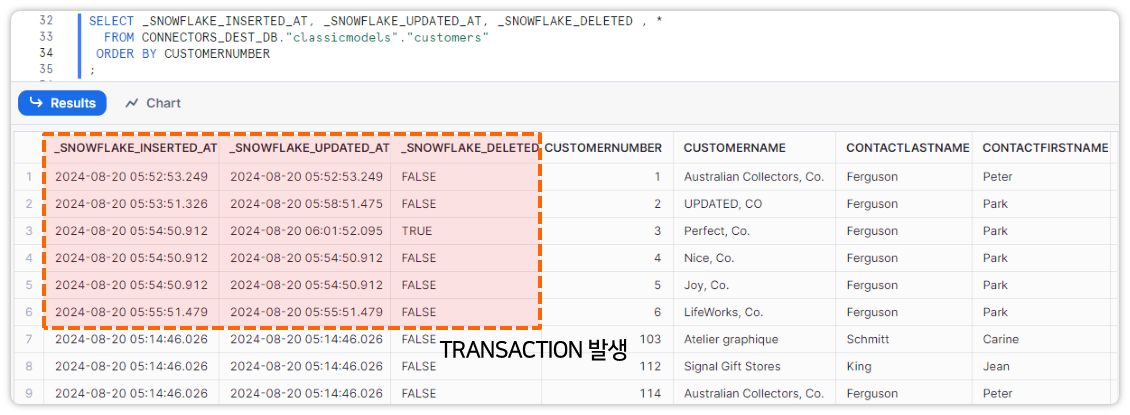
_SNOWFLKAE_INSERTED_AT, _SNOWFLAKE_UPDATED_AT, _SNOWFLAKE_DELETED_AT 과 같은 메타 컬럼이 생성된 것을 볼 수 있고 해당 컬럼들을 통해 데이터 변경 건을 확인할 수 있다.
INSERT_CHECK
- 신규 데이터 수 초 내 바로 적용
UPDATE_CHECK
- 동일 ROW의 _SNOWFLAKE_UPDATED_AT 최신화
DELETE_CHECK
- _SNOWFLAKE_DELETED 컬럼 FALSE=>TRUE 변경
최신 데이터 반영

소스 데이터베이스에서 데이터 변경이 발생하면 Agent가 이를 추적하여 Snowflake에 Push하게 된다. 이후 Snowflake 물리 테이블에 초기 데이터 및 변경분 데이터가 지속적으로 적재가 되는 구조이다. 이제 사용자가 바라보는 테이블에 신규 데이터만 반영하도록 Dynamic Table을 활용해보도록 하자.

위와 같은 사용자 기반 쿼리를 통해 최신 데이터만 반영할 수 있도록 Dynamic Table을 생성한다.

이번 시간에는 커넥터를 통해 데이터를 Snowflake로 적재해봤는데 이렇게 간단해도 되나 싶을 정도로 처음 하는 모든 사람이 따라하면 할 수 있을 정도로 간단했다. 또한 UI 기반으로 Agent를 구성하고 연결하는 과정이 체감상 더 쉽게 다가온 것 같다.
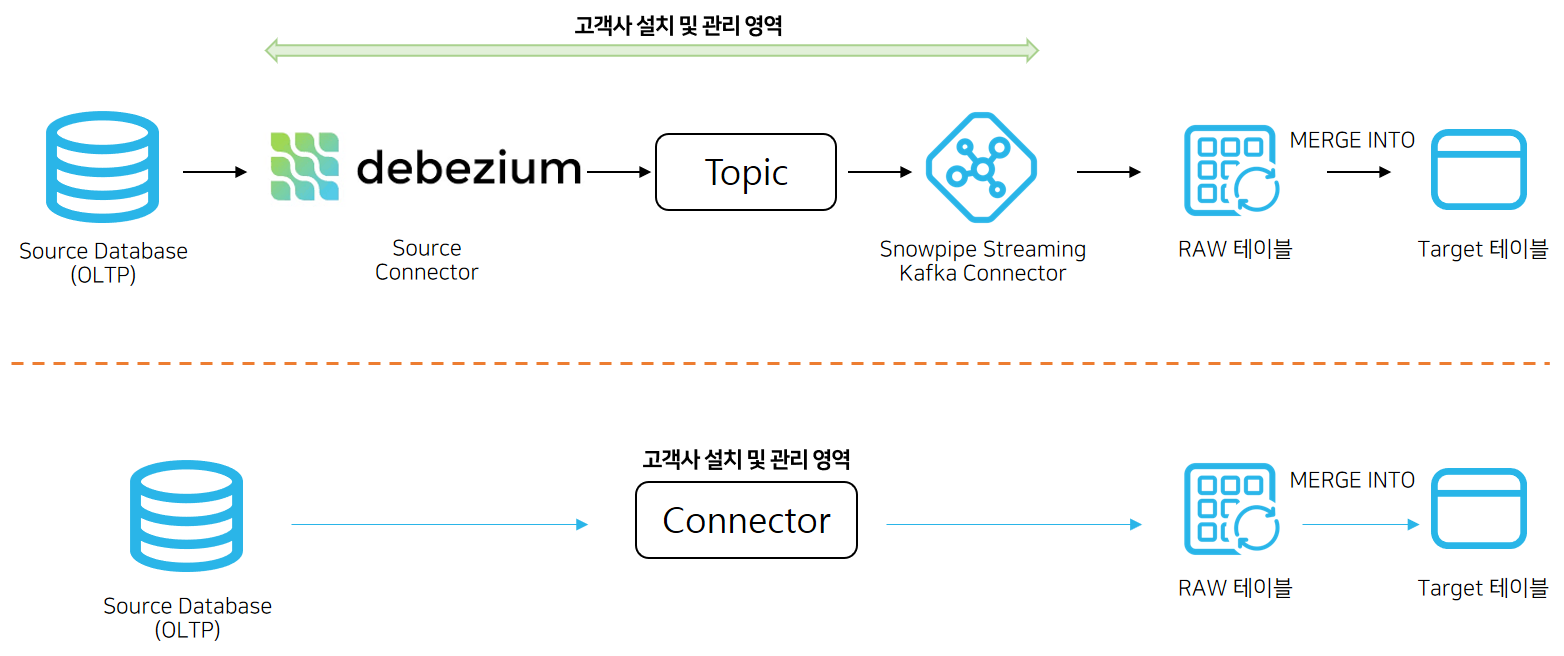
기존 AS-IS CDC 기반 데이터 수집은 debezium source 커넥터를 연결하고 Kafka 토픽에 데이터를 쌓은 뒤에 이를 Snowpipe Streaming Kafka 커넥터를 통해 Snowflake로 적재하는 방식이었다. 하지만 이러한 방식은 관리 포인트가 많다는 점도 있고 Kafka에 대한 저변 지식도 필요하다. 또한 수집 대상 테이블이 늘어날수록 Merge 하는 작업들이 늘어날 수밖에 없었는데 Native 커넥터를 활용하면 고객사에서 관리하는 포인트가 확연히 준다는 장점도 있고 무엇보다 너무나도 간단한 방법으로 데이터를 수집할 수 있다는 장점이 있다.
'Snowflake' 카테고리의 다른 글
| 배치별 수행 속도 비교 (0) | 2025.11.28 |
|---|---|
| Warehouse Dag별 모니터링 (0) | 2025.11.28 |
| Oracle에서 Snowflake로 CDC(변경 데이터 캡처) 데이터 처리 (0) | 2024.12.27 |
| [Snowflake] 웨어하우스 캐시 최적화 (1) | 2024.12.17 |
| [2] AWS PrivateLink를 이용한 Secure한 Snowflake 액세스 - Internal Stage (S3) (0) | 2024.10.16 |

